目前深度学习的训练采用了mxnet框架,接下来会从具体的应用示例出发,详细分析深度学习的具体流程和一些trick,在示例分析中穿插相关概念的介绍。
MXNet简介
mxnet是一个开源的深度学习框架,它可以使你能自行定义、训练、配置和部署深度人工神经网络,并且适用于从云端到移动端诸多不同的设备上。可快速模型训练、灵活支持各种编程模型和语言使得mxnet具有高度的可扩展性。同时,它还允许混合使用命令式与符号式编程以最大化程序的效率和性能。具体mxnet的底层实现以及同caffe、tensorflow、theano框架对比如下: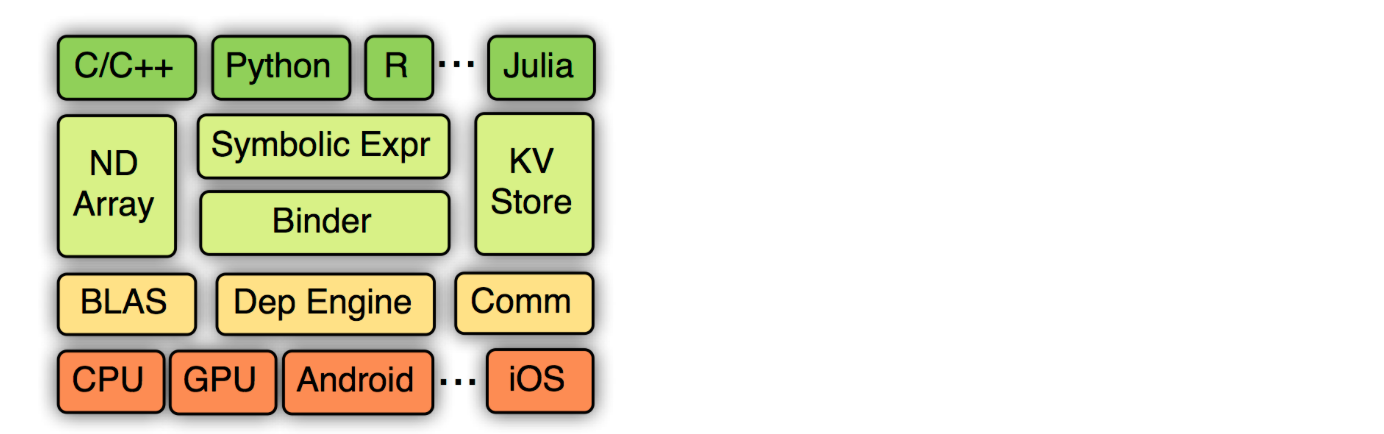
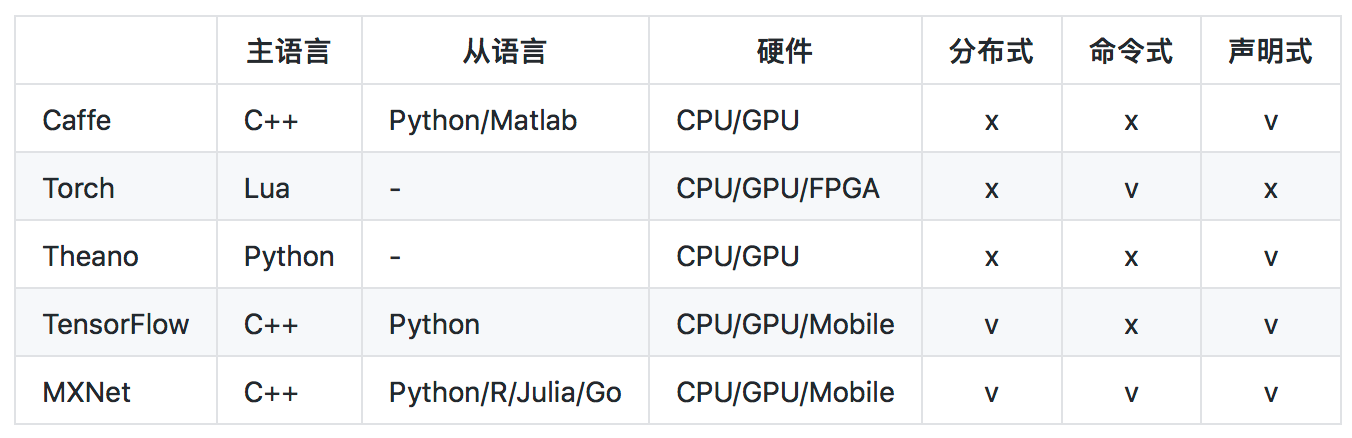
目前facebook最新发布caffe2同样支持移动端部署,具体mxnet设计和实现简介可参考官方文档https://github.com/dmlc/mxnet/issues/797?url_type=39&object_type=webpage&pos=1。
MLP手写体识别示例分析
接下来详细介绍下基于mxnet框架的mnist手写体识别,事实上在mxnet/example/image-classification/下已经存在了train_mnist.py的样例,但其分散依赖了其他文件,这里在train_mnist.py的基础上进行了重构,具体github地址为https://github.com/dreamocean/mnist,工程结构如下: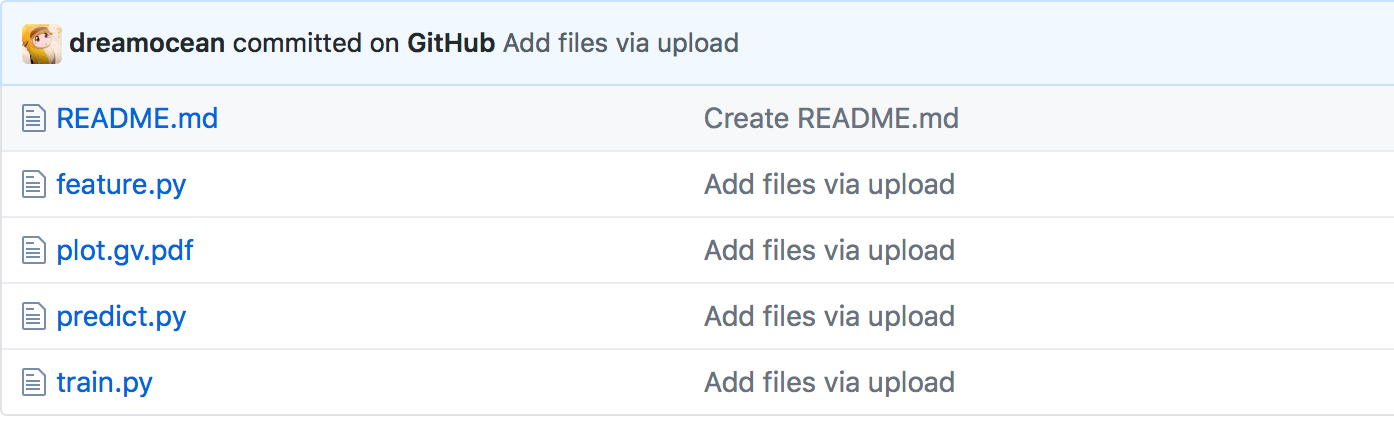
|
|
模型训练
数据准备
mnist数据显示如下:
不过官方给出的为二进制数据,具体读取方式如下:
|
|
训练数据、验证数据和测试数据的划分方式:
- 像sklearn一样,提供一个将数据集切分成训练集和测试集的函数(默认是把数据集的75%作为训练集,把数据集的25%作为测试集);
- 在机器学习领域中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set ) 和测试集(test set)。其中训练集用于模型构建,验证集用来辅助模型构建,如进一步网络调参,而测试集用于评估模型的准确率,绝对不允许用于模型构建过程,否则会导致过渡拟合。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取;
- 当样本总量少的时候,上面的划分就不合适了。常用的是留少部分做测试集,然后对其余N个样本采用K折交叉验证法(一般取十折交叉验证),具体流程为:将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据,特别的K取N时,就是留一法(leave one out)。
网络模型构建
|
|
如上所述,通过声明式的符号表达式构建了一个多层感知器模型,具体网络结构如下: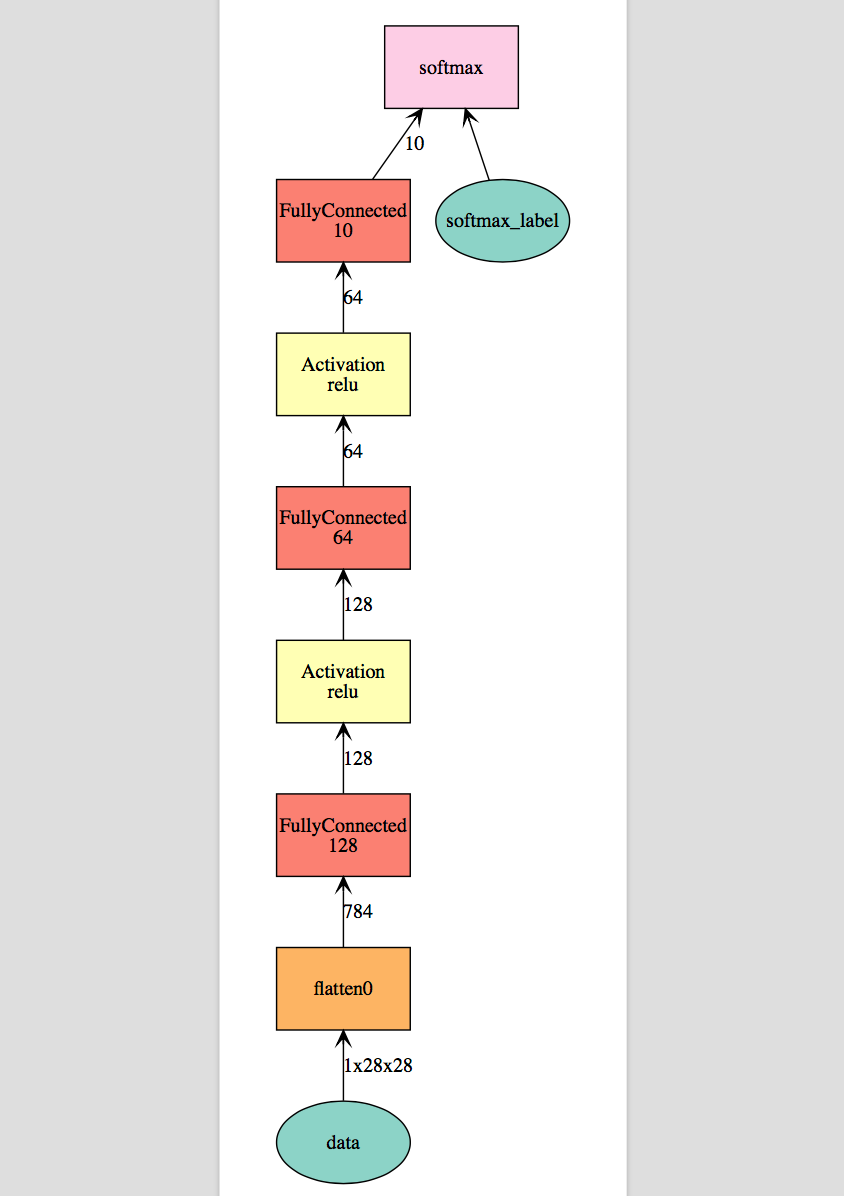
训练模型
|
|
训练模型时涉及到学习率、动量和batch_size等几个重要参数的设置,具体可参考上篇文章《深度学习中基于梯度的优化方法https://dreamocean.github.io/2017/06/12/sgd/ 》
,训练输出如下:
|
|
|
|
可以看到,相对于CPU,GPU版本耗时更低。最终训练得到我们的模型及参数:
特征输出
|
|
输出结果如下:
|
|
网络模型中采用了整流线性单元(rectified linear unit)relu激励函数,其具体表现如下: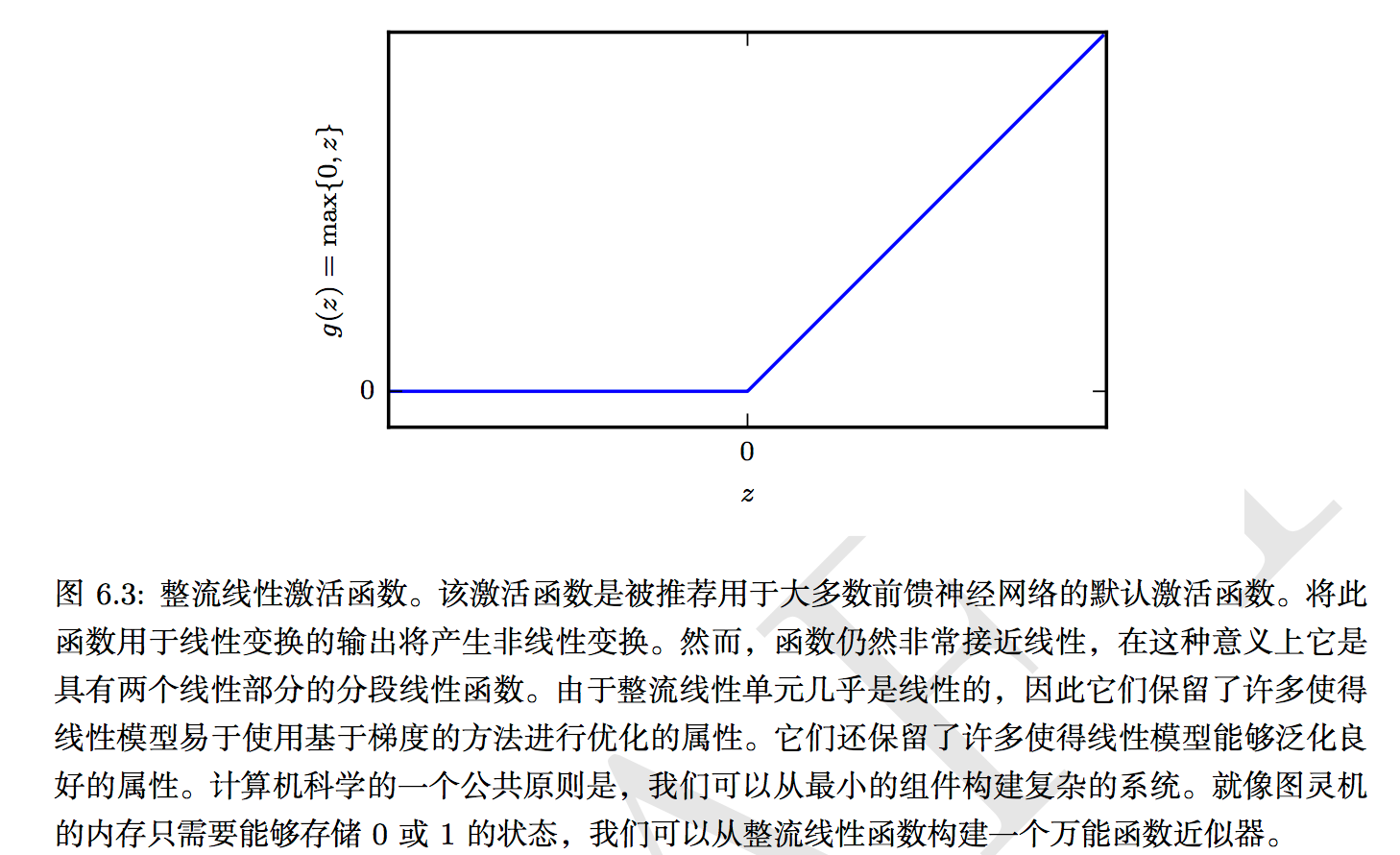
我们可以输出fc2_output层特征:
|
|
可以看到从fc2_output从relu2_output的特征变化符合relu激活函数变化结果。
symbol型变量act_type可选三种激活函数{'relu', 'sigmoid', 'tanh'}, 针对该应用场景,当激活函数为sigmoid时,训练结果相差不大;当激活函数为tanh时,10个epoch的validation为0.799左右,80个epoch的validation为0.947。
结果预测
|
|
预测结果输出如下:
|
|
