ResNet
ResNet——MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。
ResNet最根本的动机就是解决所谓的“退化”问题,即当模型的层次加深时,错误率却提高了,如下图: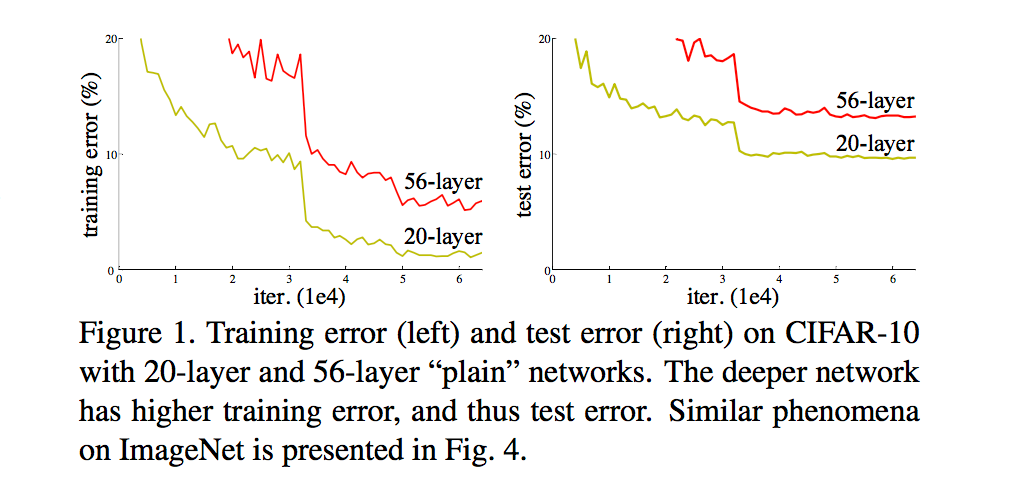
但是模型的深度加深,学习能力增强,因此更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”问题产生的原因归结于优化难题,当模型变复杂时,SGD的优化变得更加困难,导致了模型达不到好的学习效果。
针对这个问题,作者提出了一个Residual的结构: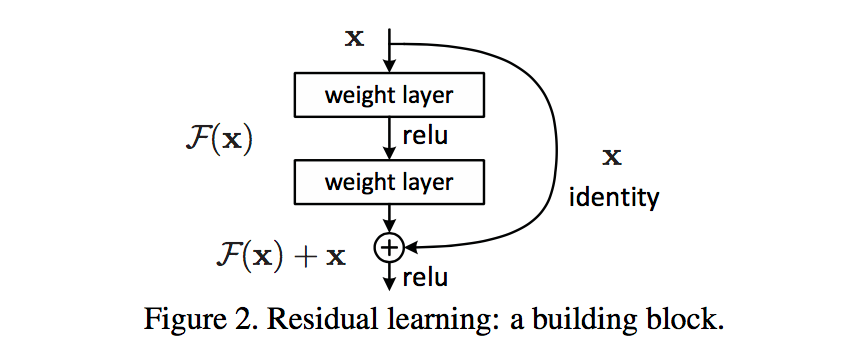
即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
作者构建了34-layer plain和34-layer residual网络,residual网络仅是在plain网络上插入了shortcut,而且这两个网络的参数量、计算量相同,并且和之前有很好效果的VGG-19相比,计算量要小很多。(36亿FLOPs VS 196亿FLOPs,FLOPs即每秒浮点运算次数。)这也是作者反复强调的地方,也是这个模型最大的优势所在,具体示意图如下: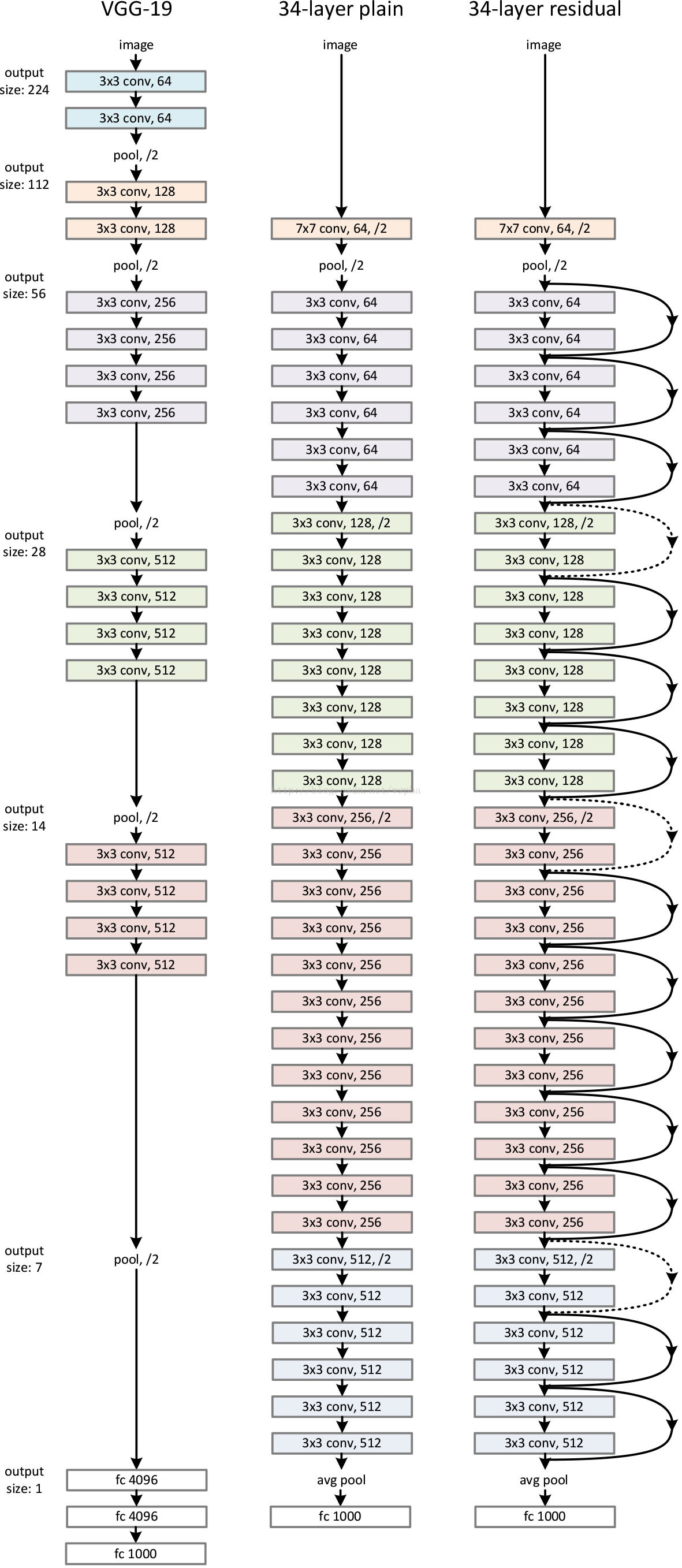
模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多: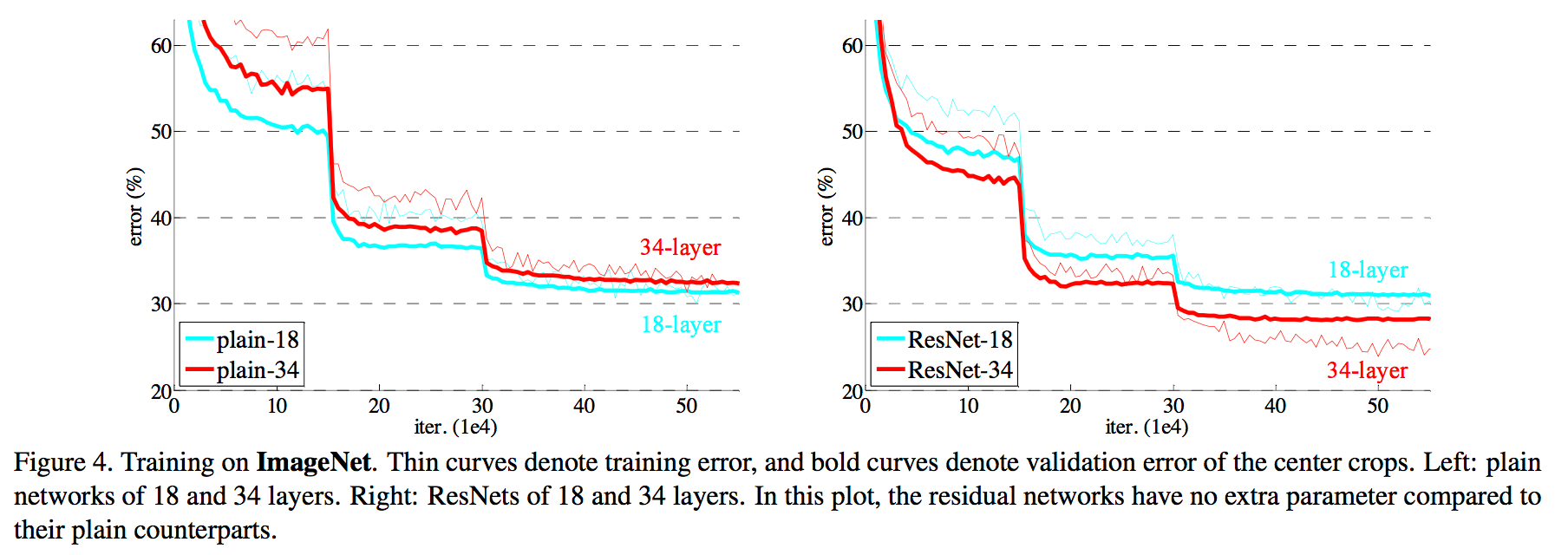
对于shortcut的方式,作者提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
进一步实验,作者又提出了deeper的residual block: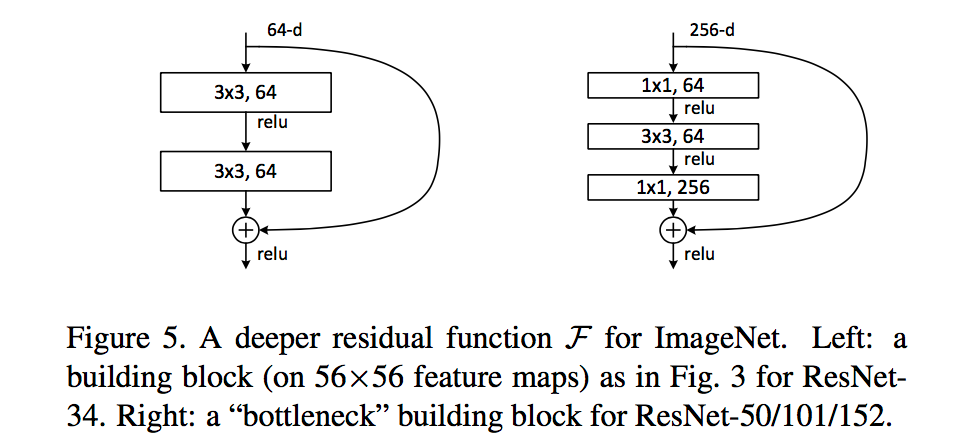
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。在imagenet上表现如下: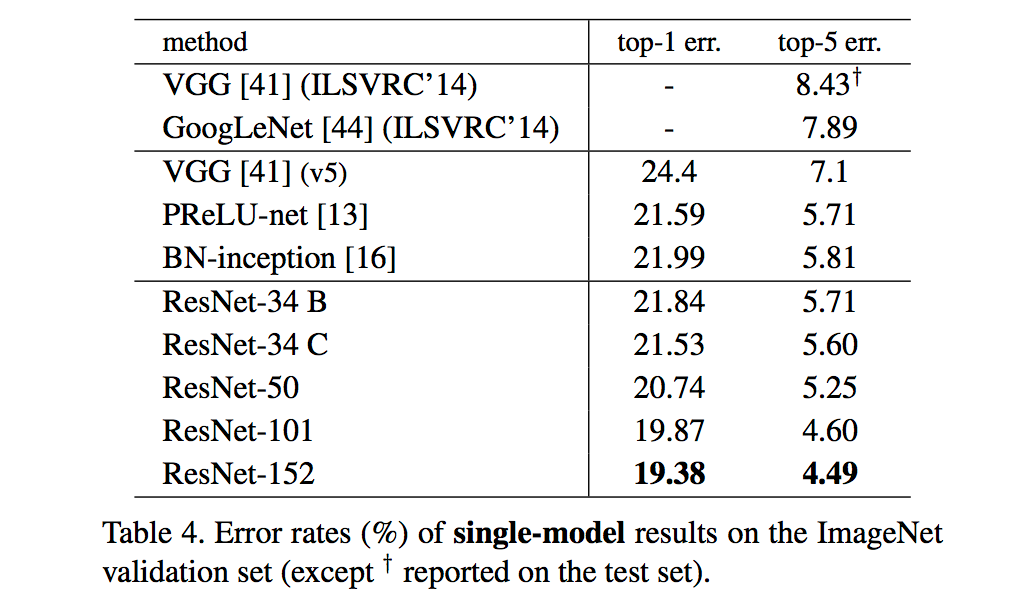
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。
ResNeXt
在ImageNet和COCO2015竞赛中,共有152层的深度残差网络ResNet在图像分类、目标检测和语义分割各个分项都取得最好成绩,相关论文更是连续两次获得CVPR最佳论文。ResNet作者之一何恺明在去到Facebook AI实验室后,继续改进工作提出了ResNeXt,参考论文Aggregated Residual Transformations for Deep Neural Networks。ResNeXt采用多分支的同构结构,只需要设定较少的超参数,并且显露出在深度、宽度之外神经网络的另一个衡量指标——“基数”(cardinality)。
提出来cardinality的概念,在上图左右有相同的参数个数,其中左边是ResNet的一个区块,右边的ResNeXt中每个分支一模一样,分支的个数就是cardinality。此处借鉴了 GoogLeNet的split-transform-merge,和VGG/ResNets的repeat layer: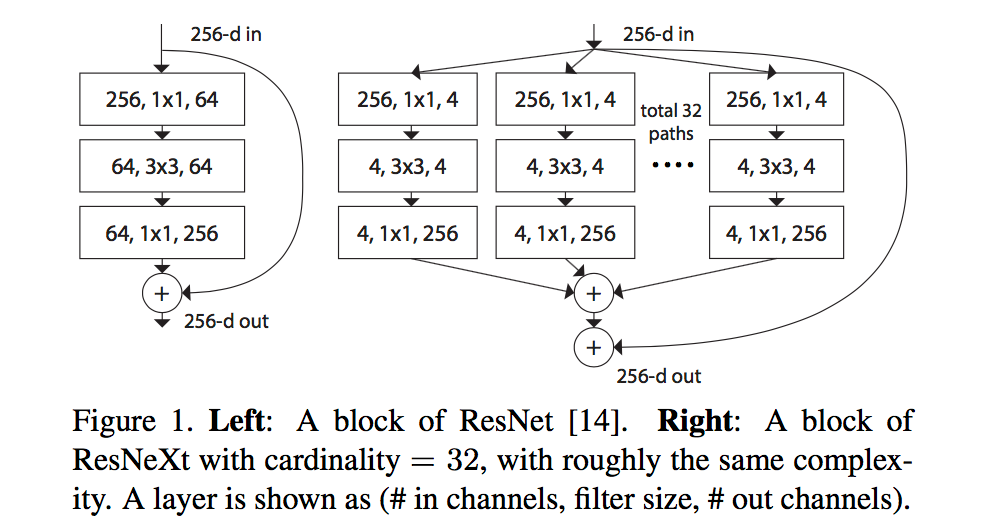
ResNext做的主要贡献为:
对于ResNet,VGG,Inception等网络,需要由一些重复的building block堆叠而成,而这些building block的滤波器个数,大小等不能任意设置,需要人工调整。由于其中有很多超参数需要调整,而且在不同的vision task甚至是不同的dataset上参数不能直接共享需要进行个性化定制,因此,这种需要为一定task或者dataset定制的module虽然效果好,但通用性太差。这篇文章介绍了一种新的building block,可以用来替换ResNet的building block,新的模型称为ResNeXt。ResNeXt的最大优势在于整个网络的building block都是一样的,不用在每个stage里再对每个building block的超参数进行调整,只用一个building block,重复堆叠即可形成整个网络。实验结果表明ResNeXt比ResNet在同样模型大小的情况下效果更好,具体表现如下图所示:
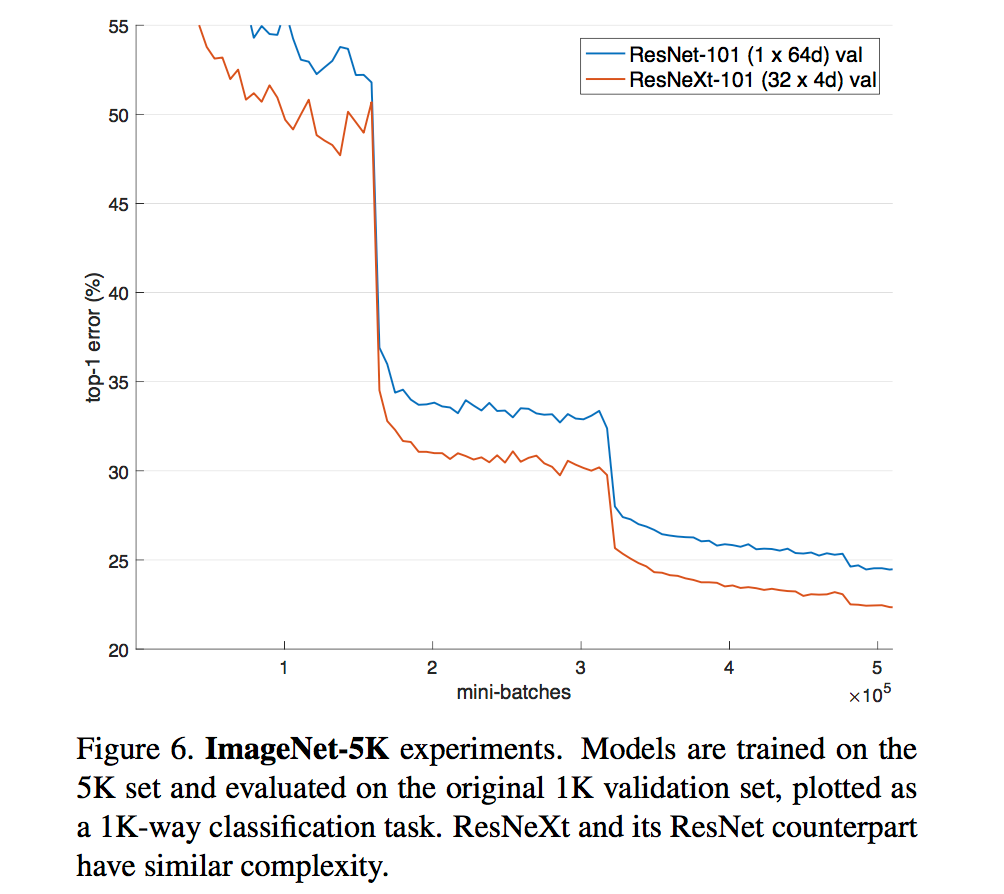
具体网络结构如下: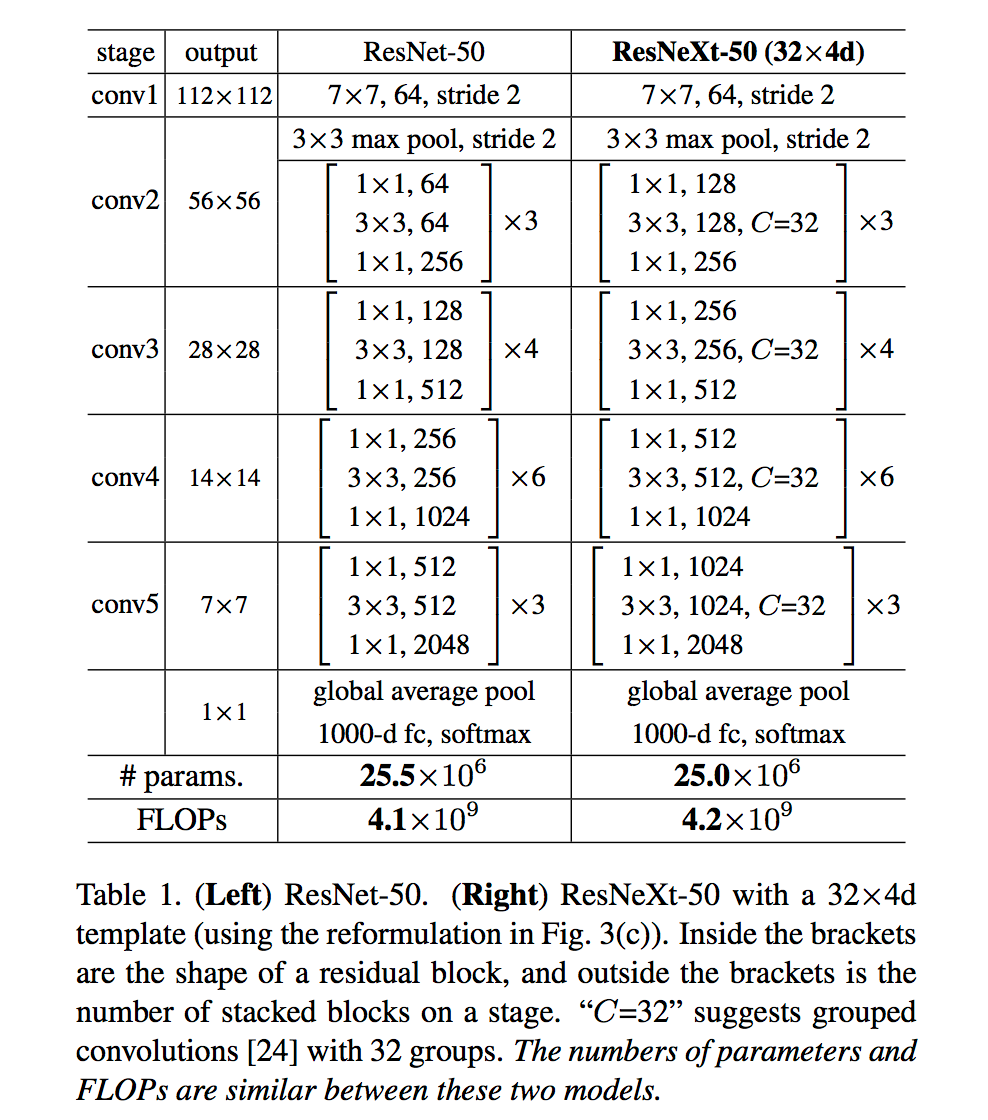
ResNeXt与Inception网络比较如下: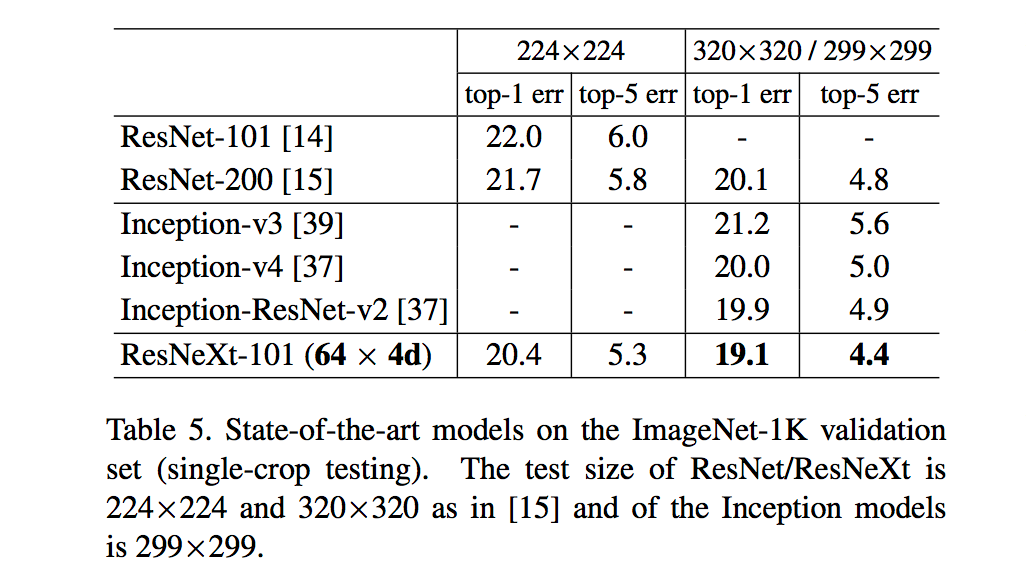
最终结论:
1、ResNeXt 与 ResNet 在相同参数个数情况下,训练时前者错误率更低,但下降速度差不多;
2、相同参数情况下,增加 cardinality 比增加深度(depth)和广度(width)几个数更加有效;
3、101层的ResNeXt比200层的ResNet更好;
4、几种模型,ResNeXt准确率最高。
wide ResNet/ResNeXt
网络不断向更深发展,但是有时候为了得到少量的精度增加,却需要将网络层数翻倍,也会减少特征的重用,降低训练速度。作者从宽度的角度,提出了wide residual network,16层的WRN表现就比之前的ResNet效果要好,具体论文参考Wide Residual Networks。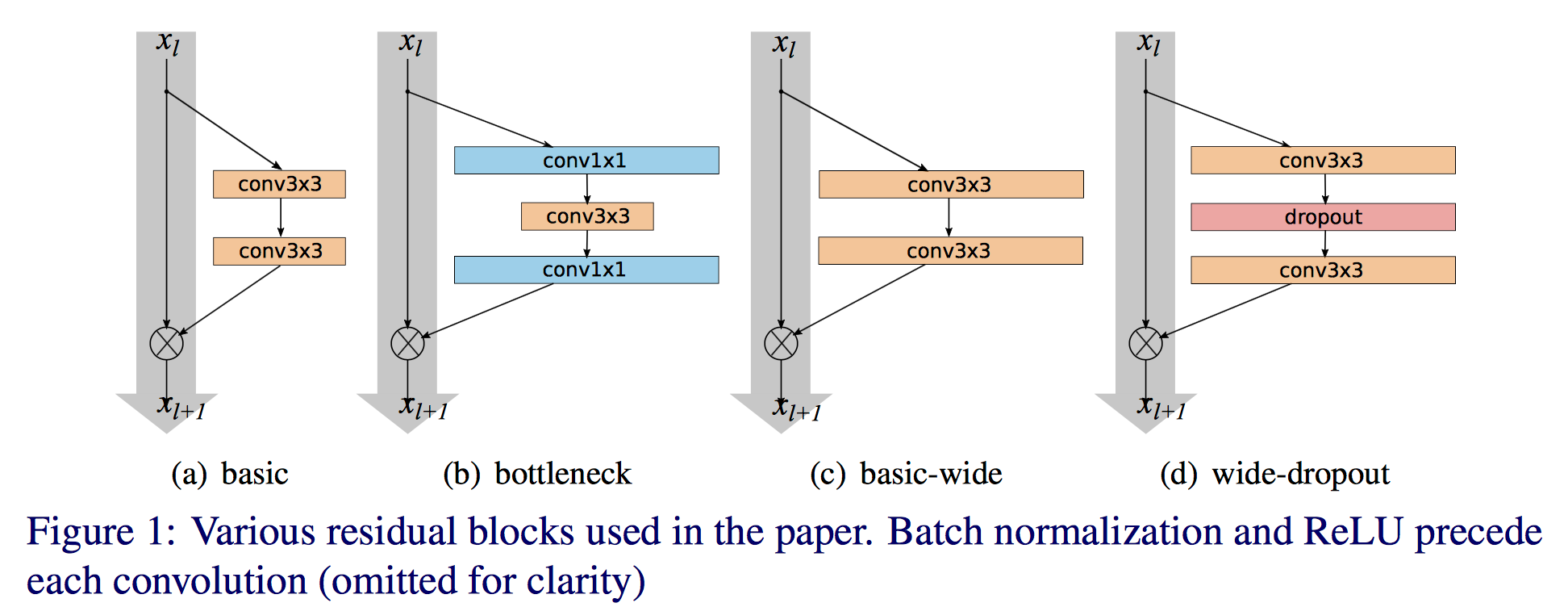
上图中a,b是kaiming提出的两种方法,b计算更节省,但是作者想看宽度的影响所以采用了a。作者提出增加residual block的三种简单途径:
- 更多卷积层;
- 加宽(more feature planes);
- 增加卷积层的滤波器的大小(filter sizes);
作者说小的滤波器更高效,所以不准备使用超过3x3的卷积核,提出了宽度放大倍数k和卷积层数l,作者的结构: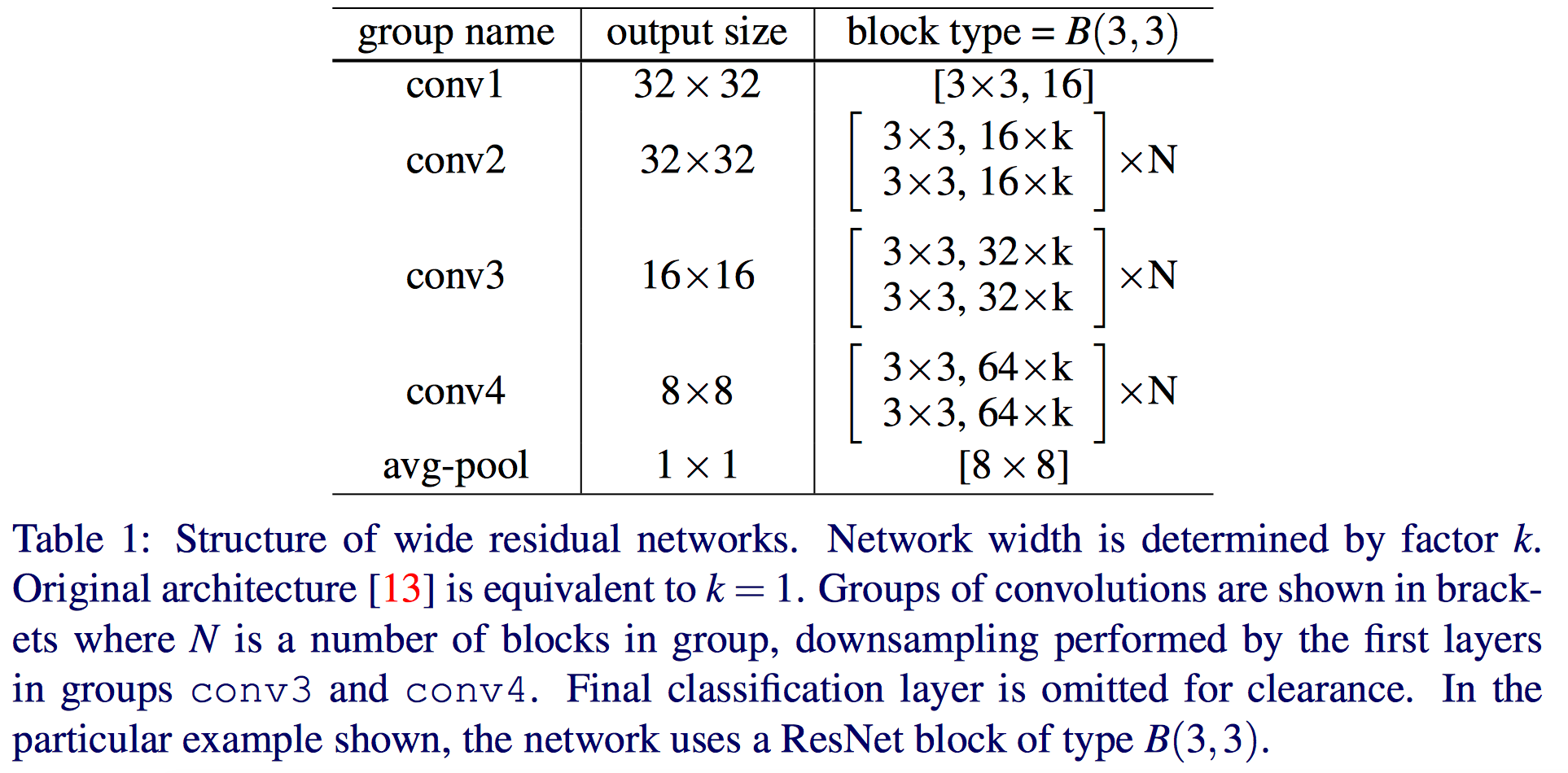
作者发现,参数会随着深度的增加成线性增长,但是随着宽度却是平方增大。虽然参数会增多,但是卷积运算更适合gpu。 参数的增多需要正则化(regularization)来减少过拟合,何凯明等人使用了batch normalization,可是这种方法需要heavy augmentation,作者使用了dropout。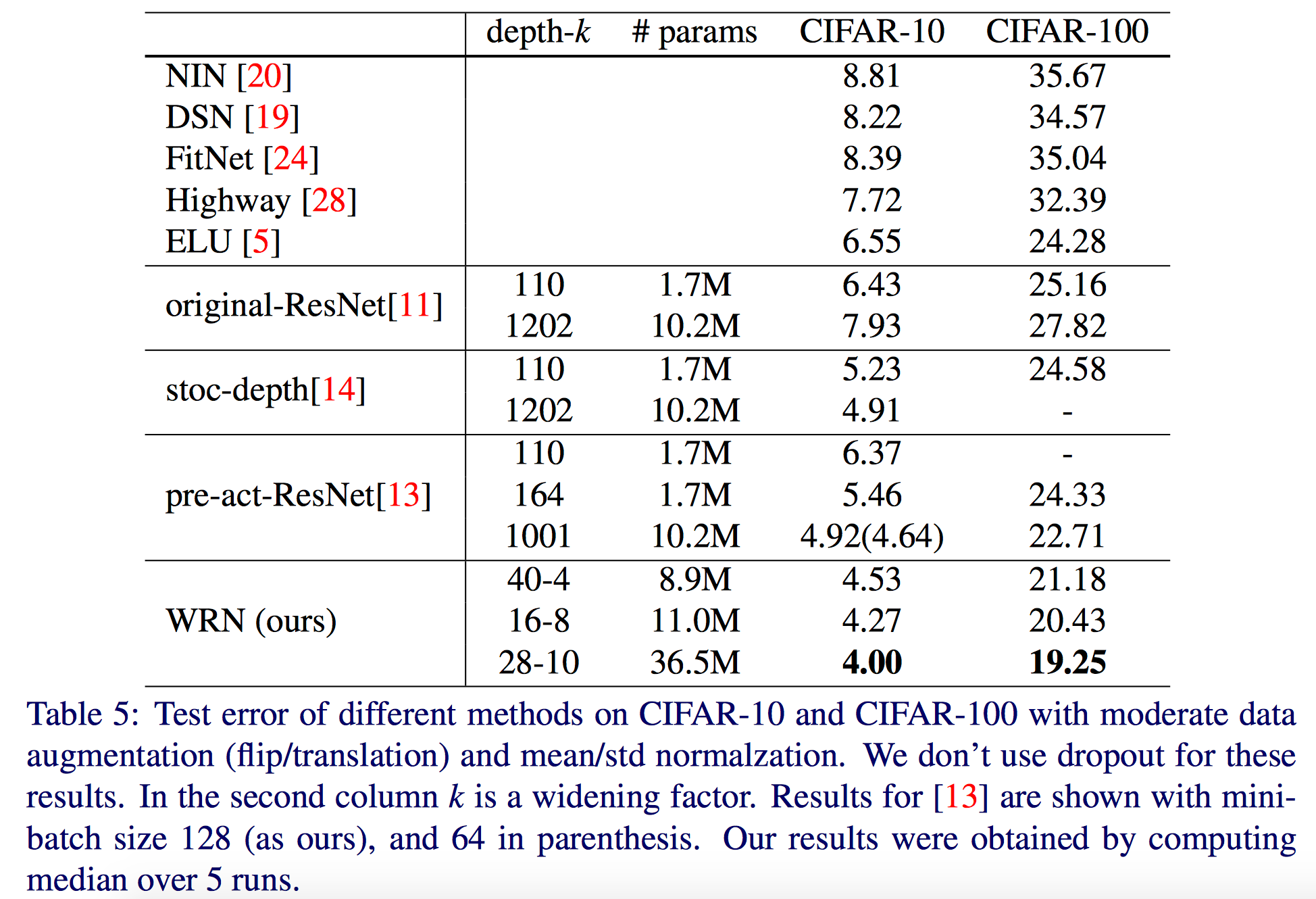
WRN40-4与ResNet1001结果相似,参数数量相似,但是前者训练快8倍。总结如下:
- 宽度的增加提高了性能;
- 增加深度和宽度都有好处,直到参数太大,正则化不够;
- 相同参数时,宽度比深度好训练;
dropout的影响如下: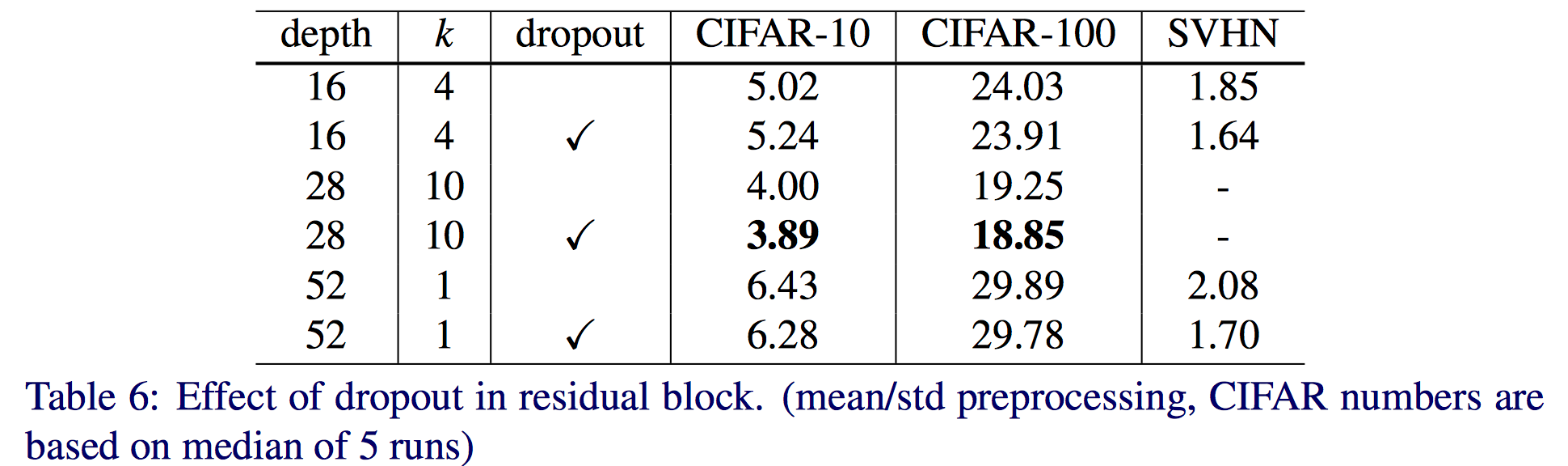
对于参数较少的16-4得到的结果反而差了。
参考文章:
http://www.vccoo.com/v/1807u1?source=rss
http://www.cnblogs.com/lillylin/p/6799173.html
http://blog.csdn.net/xuanwu_yan/article/details/53455260?winzoom=1
