目前的人脸检测方法主要有两大类:基于知识和基于统计。
基于知识的方法:主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸,如模板匹配、人脸特征、形状与边缘、纹理特性、颜色特征。
基于统计的方法:将人脸看作一个整体的模式(二维像素矩阵),从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量来判断人脸是否存在,如主成分分析与特征脸、神经网络方法、支持向量机、隐马尔可夫模型、Adaboost算法。
这里主要介绍OpenCV内部集成的基于Haar特征与Adaboost的人脸检测算法haarcascade。OpenCV安装目录中的\data\haarcascades目录下的haarcascade_frontalface_alt.xml与haarcascade_frontalface_alt2.xml都是用来检测人脸的Haar分类器,其中包含了描述人脸的Haar特征值。这个haarcascades目录下还有人的全身,眼睛,嘴唇的Haar分类器。xml文件结构如下: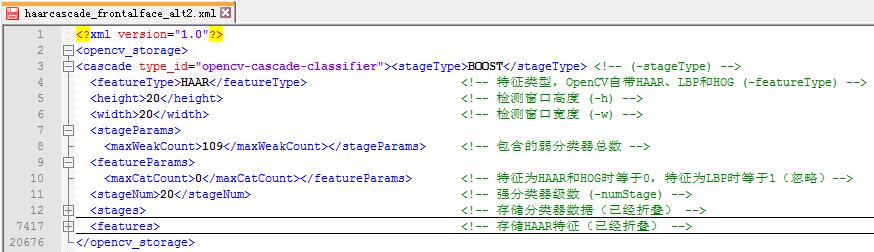
Haar特征
什么是特征?
我们可以在如下情景中来描述,假设在人脸检测时我们需要有这么一个子窗口在待检测的图片窗口中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的级联分类器对该特征进行筛选,一旦该特征通过了所有强分类器的筛选,则判定该区域为人脸。
那么这个特征如何表示呢?
Viola等人提出的Haar-like特征如下: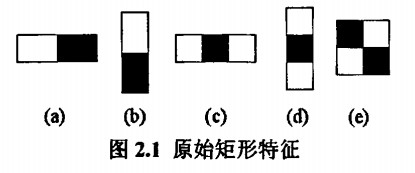
Lienhart等人提出的扩展Haar-like特征如下: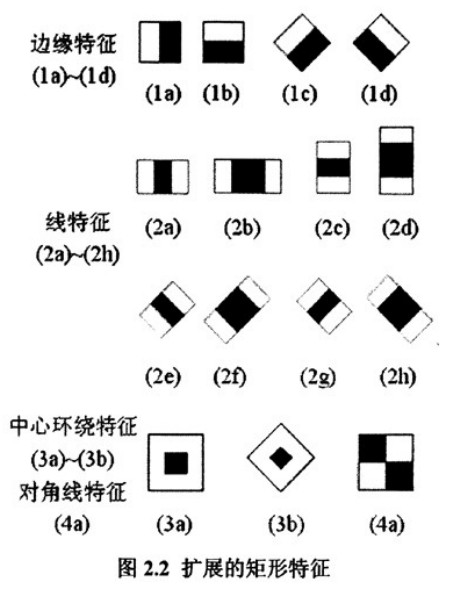
将矩形白色区域的像素和减去黑色区域的像素和,得到的值我们暂且称之为人脸特征值,以区分人脸和非人脸。为了增加区分度,可以通过boost手段对多个矩形特征计算得到一个区分度更大的特征值。
Adaboost
基于PAC学习模型的理论分析,Valiant提出了Boosting算法,Boosting算法涉及到两个重要的概念就是弱学习和强学习:
弱学习:就是指一个学习算法对一组概念的识别率只比随机识别好一点;
强学习:就是指一个学习算法对一组概率的识别率很高。
Kearns和Valiant提出了弱学习和强学习等价的问题,并证明了只要有足够的数据,弱学习算法就能通过集成的方式生成任意高精度的强学习方法。这一证明使得Boosting有了可靠的理论基础,Boosting算法成为了一个提升分类器精确性的一般性方法。
然而,Boosting算法还是存在着几个主要的问题:
一、Boosting算法需要预先知道弱学习算法学习正确率的下限,即弱分类器的误差;
二、Boosting算法可能导致后来的训练过分集中于少数特别难区分的样本,导致不稳定。
针对Boosting的若干缺陷,Freund和Schapire于1996年前后提出了一个实际可用的自适应Boosting算法AdaBoost,AdaBoost目前已发展出了大概四种形式的算法,Discrete AdaBoost(AdaBoost.M1)、Real AdaBoost、LogitBoost、gentle AdaBoost,这里不做一一介绍,下面将详细介绍haarcascade中的Adaboost结构。
弱分类器
一个完整的弱分类器包含:Haar特征+leftValue+rightValue+弱分类器阈值(threshold),这些元素共同构成了弱分类器,缺一不可。haarcascade_frontalface_alt2.xml的弱分类器深度为2,包含了2种形式,如下图所示,图中的左边形式包含2个Haar特征、1个leftValue、2个rightValue和2个弱分类器阈(t1和t2);右边形式包括2个Haar特征、2个leftValue、1个rightValue和2个弱分类器阈。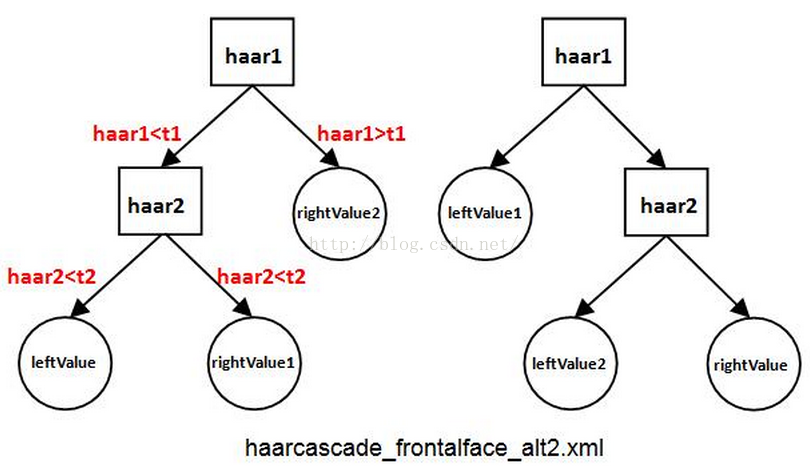
以左图为例,可通过如下步骤计算弱分类器输出值:
1、计算第一个Haar特征的特征值haar1,与第一个弱分类器阈值t1对比,当haar1
t1时,该弱分类器输出rightValue2并结束。
2、计算第二个Haar特征值haar2,与第二个弱分类器阈值t2对比,当haar2t2时输出rightValue1。
强分类器
在OpenCV中,强分类器是由多个弱分类器“并列”构成,即强分类器中的弱分类器是两两相互独立的。在检测目标时,每个弱分类器独立运行并输出cascadeLeaves[leafOfs-idx]值,然后把当前强分类器中每一个弱分类器的输出值相加,即:sum+= cascadeLeaves[leafOfs - idx],具体示意如下: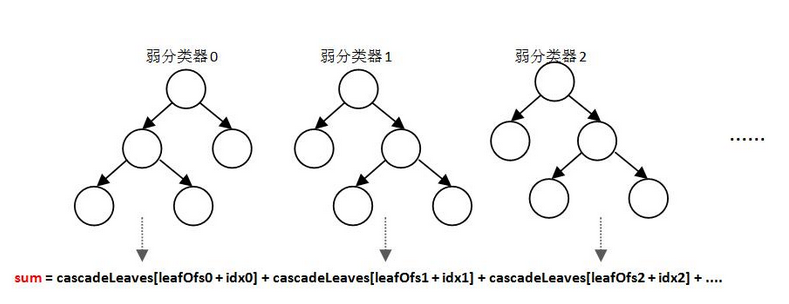
之后与本级强分类器的stageThreshold阈值对比,当且仅当结果sum>stageThreshold时,认为当前检测窗口通过了该级强分类器。当前检测窗口通过所有强分类器时,才被认为是一个检测目标。可以看出,强分类器与弱分类器结构不同,是一种类似于“并联”的结构,我称其为“并联组成的强分类器”。
级联分类器
由弱分类器“并联”组成强分类器,而由强分类器“串联”组成级联分类器,具体示意图如下: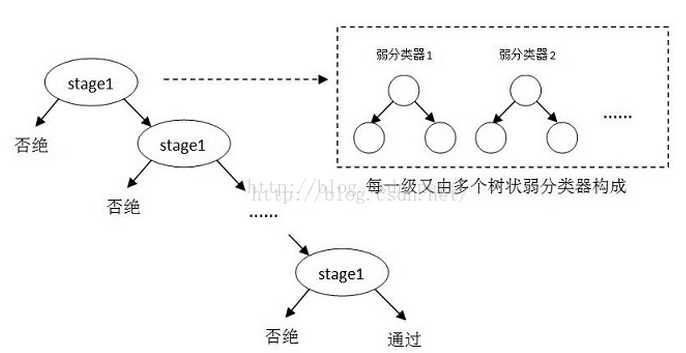
其中每一个stage都代表一级强分类器。当检测窗口通过所有的强分类器时才被认为是目标,否则拒绝。
检测窗口
检测窗口大小固定(例如alt2是20*20像素)的级联分类器如何遍历图像,以便找到在图像中大小不同、位置不同的目标:
1、为了找到图像中不同位置的目标,需要逐次移动检测窗口(随着检测窗口的移动,窗口中的Haar特征相应也随着窗口移动),这样就可以遍历到图像中的每一个位置;
2、而为了检测到不同大小的目标,一般有两种做法:逐步缩小图像或逐步放大检测窗口。 缩小图像就是把图像长宽同时按照一定比例(默认1.1 or 1.2)逐步缩小,然后检测;放大检测窗口是把检测窗口长宽按照一定比例逐步放大,这时位于检测窗口内的Haar特征也会对应放大,然后检测。一般来说,如果用软件实现算法,则放大检测窗口相比运行速度更快。
积分思想
对于Harr特征检测人脸,每遇到一个图片样本,每遇到一个子窗口图像,我们都面临着如何计算当前子图像特征值的问题,一个Haar-like特征在一个窗口中怎样排列能够更好的体现人脸的特征,这是未知的,所以才要训练,而训练之前我们只能通过排列组合穷举所有这样的特征,仅以Viola提出的最基本四个特征为例,在一个24×24size的窗口中任意排列至少可以产生数以10万计的特征,对这些特征求值的计算量是非常大的。而积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。
代码示例
工程地址githubhttps://github.com/dreamocean/face_detect_harr
|
|
结果输出:
参考文章:
http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
http://www.aichengxu.com/data/1501259.htm
