算法详解
在RCNN和Fast RCNN之后,Ross B. Girshick团队在2016年提出了新的Faster RCNN,在结构上,Faster RCN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,尤其是在检测速度上,简单网络目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%;复杂网络达到5fps,准确率78.8%。具体参考论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks。下面将简单介绍RCNN和Fast RCNN,再引申到Faster RCNN算法。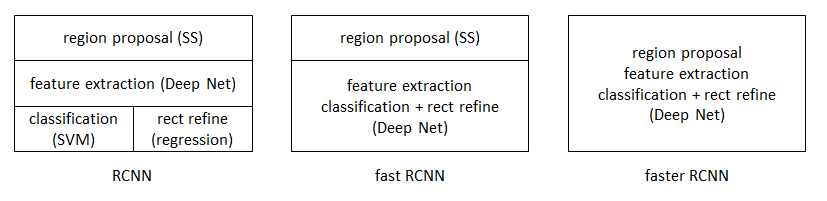
RCNN
(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的Region Proposal;
(3)将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征;
(4)将每个Region Proposal提取的CNN特征输入到SVM进行分类;
(5)对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标。
算法缺陷:
(1)训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器;
(2)训练耗时,占用磁盘空间大;5000张图像产生几百G的特征文件;
(3)速度慢:使用GPU,VGG16模型处理一张图像需要47s;
(4)测试速度慢:每个候选区域需要运行整个前向CNN计算;
(5)SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新。
Fast RCNN
目标检测步骤如下:
(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
(3)将整张图片输入CNN,进行特征提取;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练。
与RCNN不同处:
(1)最后一层卷积层后加了一个ROI pooling layer;
(2)损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。
相对RCNN的缺陷做的改进:
(1)测试时速度慢:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成的图像都会单独通过CNN提取特征,实际上这些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费。
FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享。
(2)训练时速度慢:R-CNN在训练时,是在采用SVM分类之前,把通过CNN提取的特征存储在硬盘上。这种方法造成了训练性能低下,因为在硬盘上大量的读写数据会造成训练速度缓慢。
FAST-RCNN在训练时,只需要将一张图像送入网络,每张图像一次性地提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算且不再需要把大量数据存储在硬盘上。
(3)训练所需空间大:R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间。
FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储。
Faster RCNN
目标检测步骤如下:
1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
与Fast RCNN不同处:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享。
相对于Fast RCNN做的改进:
高效快速生成建议框,Faster RCNN创造性地采用卷积网络RPN自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高。
Faster RCNN网络结构如下: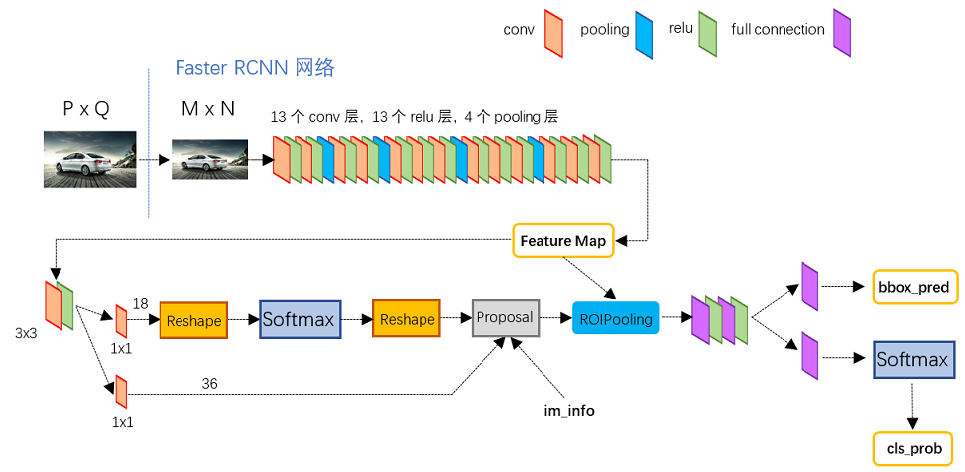
Region Proposal Networks(RPN)
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如RCNN使用SS(Selective Search)方法生成检测框。
SS算法策略如下:
算法借助了层次聚类的思想,将层次聚类的思想应用到区域的合并上面,具体思路如下:
1、假设现在图像上有n个预分割的区域(Efficient Graph-Based Image Segmentation),表示为R={R1, R2, …, Rn};
2、计算每个region与它相邻region(注意是相邻的区域)的相似度,这样会得到一个n*n的相似度矩阵(同一个区域之间和一个区域与不相邻区域之间的相似度可设为NaN),从矩阵中找出最大相似度值对应的两个区域,将这两个区域合二为一,这时候图像上还剩下n-1个区域;
3、重复上面的过程(只需要计算新的区域与它相邻区域的新相似度,其他的不用重复计算),重复一次,区域的总数目就少1,知道最后所有的区域都合并称为了同一个区域(即此过程进行了n-1次,区域总数目最后变成了1)。
而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster RCNN的巨大优势,能极大提升检测框的生成速度。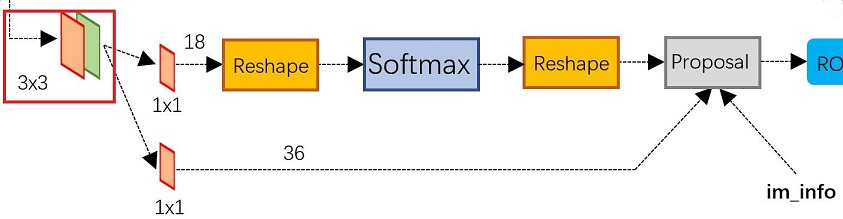
从上图可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground),下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
工程示例
Mxnet已经实现了Faster R-CNN,具体工程路径为mxnet/example/rcnn,执行流程如下:
bash script/additional_deps.sh–获取依赖库bash script/get_voc.sh–获取训练数据bash script/get_pretrained_model.sh– 获取预训练好的模型,方便fine-tuning,加速训练bash script/resnet_voc0712 0– 启动训练
训练结果输出如下: 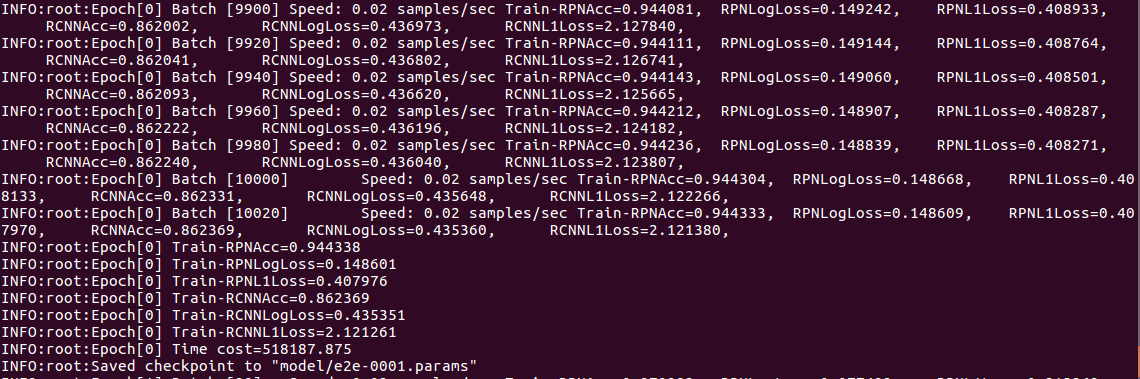
模型和参数保存在mxnet/example/rcnn/model目录下。
使用训练好的模型执行检测: python demo.py --prefix ./model/e2e --epoch 1 --image 3.jpeg
结果输出如下: 

其他测试结果如下:
| result1 | result2 |
|---|---|
 |
 |
性能分析
与Selective Search方法相比,当每张图生成的候选区域从2000减少到300时,RPN方法的召回率下降不大,说明RPN方法的目的性更明确,如下图所示: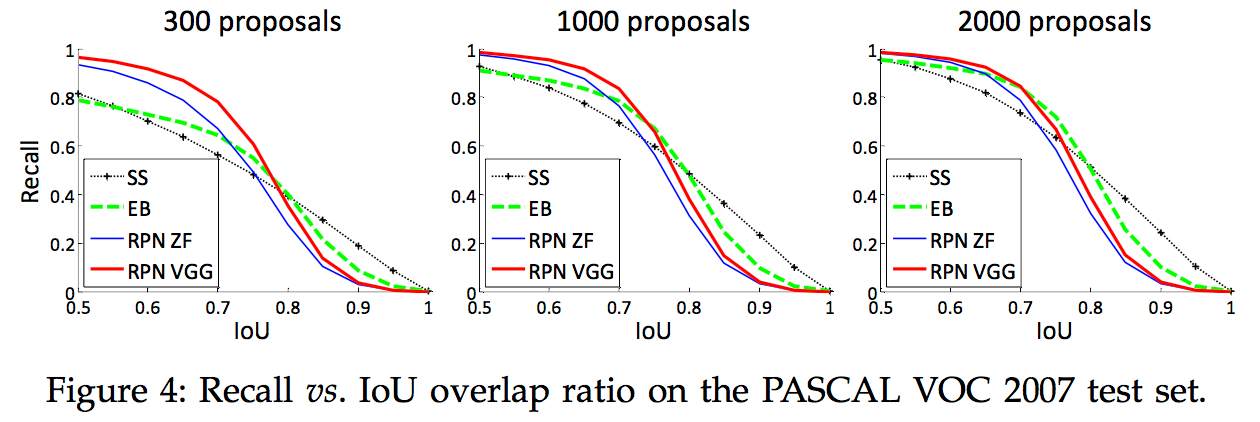
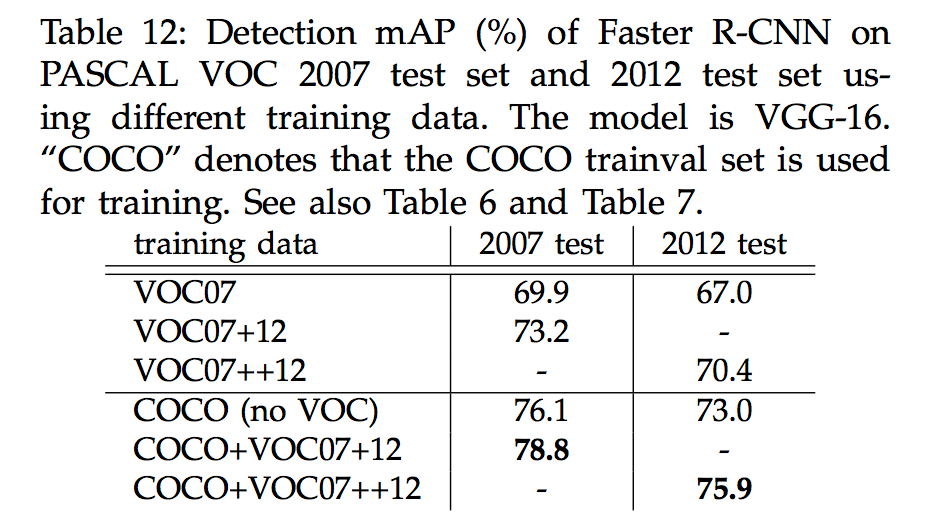
使用更大的Microsoft COCO库训练,直接在PASCAL VOC上测试,准确率提升6%,说明faster RCNN迁移性良好,没有over fitting,具体结果如下: