算法详解
从RCNN到Faster RCNN的目标检测算法一直基于region proposal和分类的思想,region proposal输出目标区域,也就是目标的位置信息,而分类提供类别信息,虽然精度已经很高了,但是实时性并不强。YOLO提供了另一种更为直接的思路:将物体检测作为回归问题求解,基于一个单独的end-to-end网络,整张图作为网络的输入,直接在输出层回归bounding box的位置和类别,完成从原始图像的输入到物体位置和类别的输出。具体参考论文You Only Look Once: Unified, Real-Time Object Detection,另外作者也提供了工程实现的官网https://pjreddie.com/darknet/yolo/。
YOLO目标检测流程如下: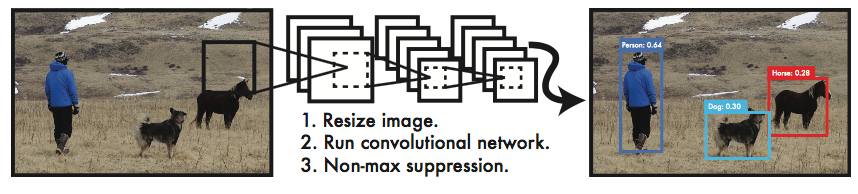
1、Resize成448*448,图片分割得到S*S网格(cell);
2、CNN提取特征和预测:各个cell的bounding box(bbox) 的坐标和是否有物体的confidence;各个cell所属20个类别的概率。
3、通过nms过滤bbox。
具体示意图如下: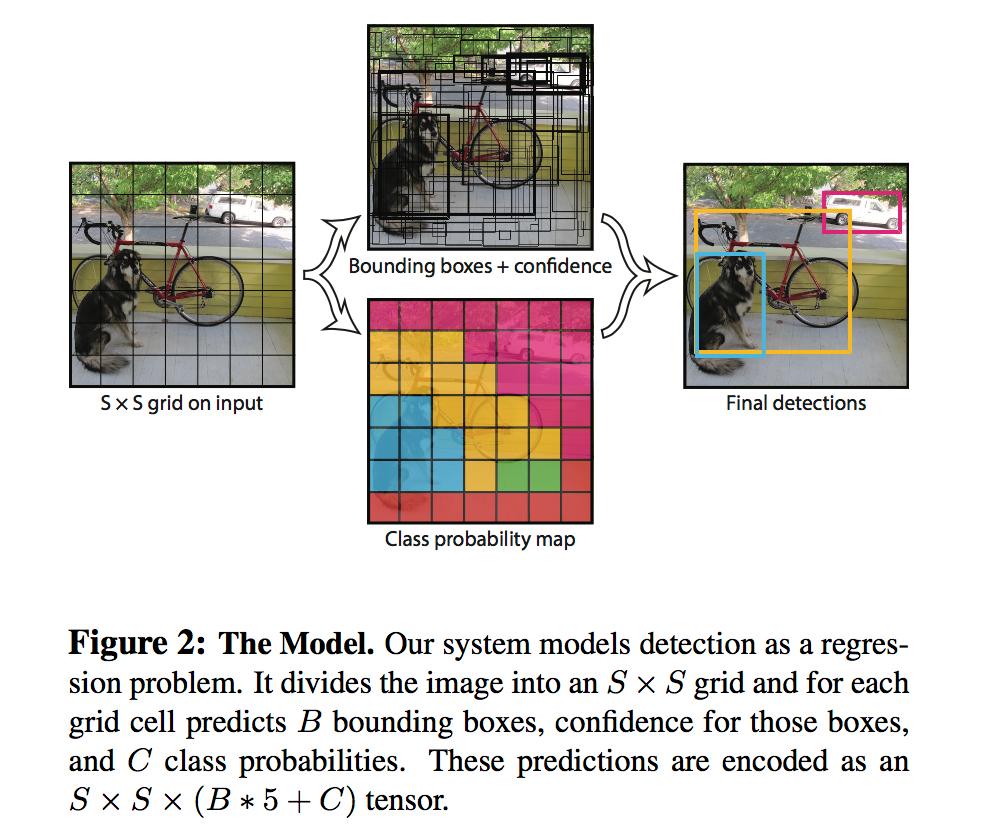
YOLO与其他检测算法的区别如下:
1、YOLO训练和检测均是在一个单独网络中进行,没有显示地求取region proposal的过程。而rcnn/fast-rcnn采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster-rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective search模块,将RPN集成到fast-rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast-rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast-rcnn网络;
2、YOLO将物体检测作为一个回归问题进行求解,整张图片作为输入,网络把图片分成不同的区域,然后给出每个区域的边框预测和概率,并依据概率大小对所有边框分配权重。最后,设置阈值,只输出得分超过阈值的检测结果。而rcnn/fast-rcnn/faster-rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题);
3、YOLO的实时性和泛化能力有明显提升,使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
4、相比RCNN系列物体检测方法,YOLO的识别物体位置精准性差,召回率低。
网络结构
YOLO检测网络包括24个卷积层和2个全连接层,其中卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值,示意图如下:
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLO论文中,作者还给出一个更轻快的检测网络Fast YOLO,它只有9个卷积层和2个全连接层。使用titan x GPU,Fast YOLO可以达到155fps的检测速度,但是mAP值也从YOLO的63.4%降到了52.7%,但却仍然远高于以往的实时物体检测方法(DPM)的mAP值。
为提高物体定位精准性和召回率,YOLO作者提出了YOLO9000,提高训练图像的分辨率,引入了faster rcnn中anchor box的思想,对各网络结构及各层的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,联合使用coco物体检测标注数据和imagenet物体分类标注数据训练物体检测模型。相比YOLO,YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
工程示例
YOLO有基于tensorflow和Darknet的实现,这里介绍Darknet的实现。Darknet是使用C和CUDA编写的轻型神经网络框架,速度快,安装简单,支持CPU和GPU,具体安装参考项目主页https://pjreddie.com/darknet/。
YOLO基于Darknet的实验和训练流程可以参考https://pjreddie.com/darknet/yolo/,这里直接下载基于VOC数据预训练好的参数yolo.weights进行目标检测测试。
输入:cd /Users/yangmzhang/Workspace/darknet-master./darknet detect cfg/yolo.cfg yolo.weights data/6.jpg
输出如下:
|
|

yolo.weights是基于Pascal VOC 2012数据集进行训练的,能够检测出20种Pascal对象:
人person
鸟bird、猫cat、牛cow、狗dog、马horse、羊sheep
飞机aeroplane、自行车bicycle、船boat、巴士bus、汽车car、摩托车motorbike、火车train
瓶子bottle、椅子chair、餐桌dining table、盆景potted plant、沙发sofa、显示器tv/monitor
一些测试结果如下:
| result1 | result2 |
|---|---|
 |
 |
结果统计: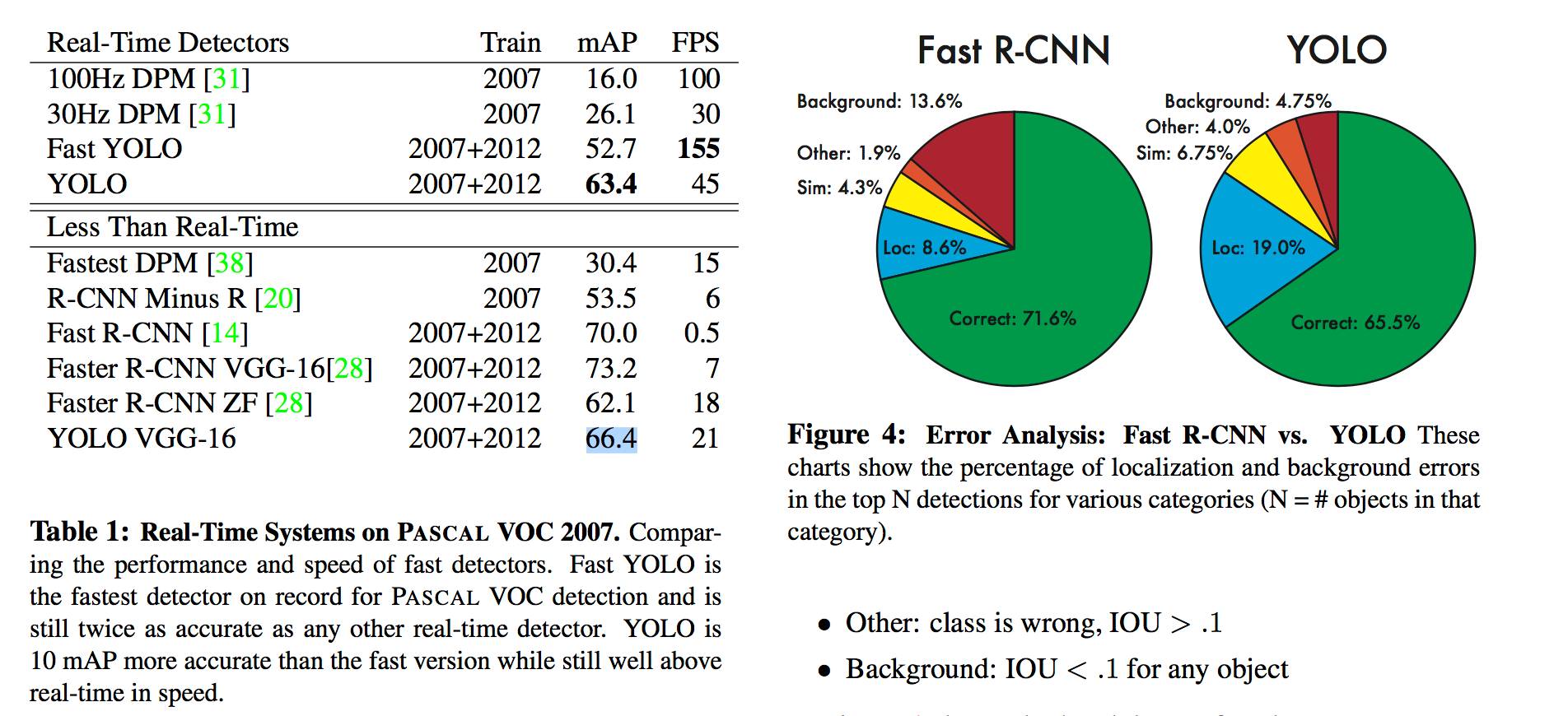
如上图所示。YOLO的实时性非常强,而且对背景内容的误判率(4.75%)比Fast R-CNN的误判率(13.6%)低很多。但是YOLO的定位准确率较差,占总误差比例的19.0%,而Fast R-CNN仅为8.6%。
