Triplet Loss
Triplet loss是Google团队在FaceNet中提出的基于度量学习的loss function,具体参考论文FaceNet•A Unified Embedding for Face Recognition and Clustering。
Triplet是一个三元组,其构成如下:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor属于同一类的样本和不同类的样本,这两个样本对应的称为Positive和Negative,由此构成一个(Anchor,Positive,Negative)三元组。Triplet loss的目的就是通过学习,让同类样本的特征表达间距尽可能小,而异类样本的特征表达间距尽可能大,示意图如下: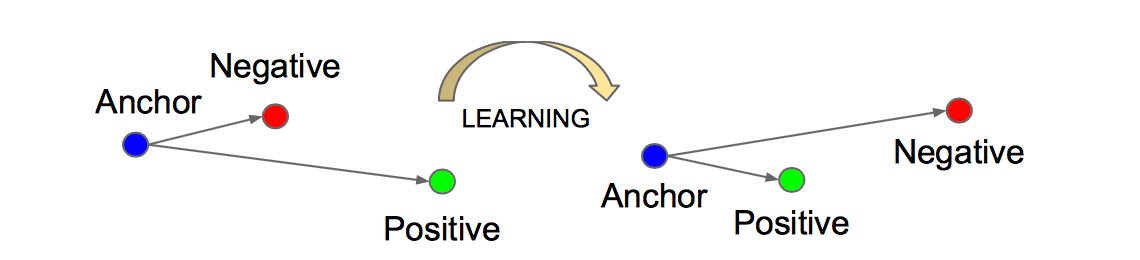
数学表达式如下: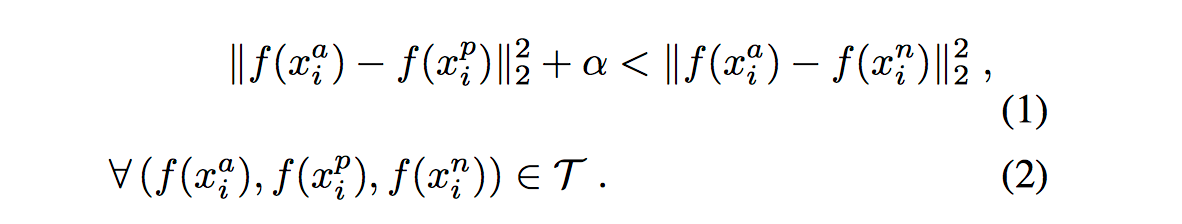
其中f(x)分别为参考样本、同类样本和异类样本的特征表达,alpha为特定阈值,保证有一个最小的间隔。
最终的loss function如下: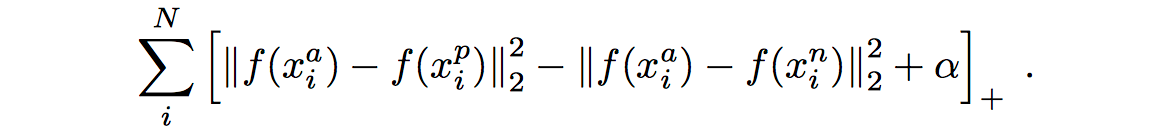
这里距离用欧式距离度量,+表示[]内的值大于零的时候,取该值为损失,小于零的时候,损失为零,算法的目标就是最小化该函数。
Triplet loss注意应用于类似人脸识别、车辆识别等个体级别精细化识别任务中,可以学习到更好的特征描述,但是收敛速度慢,容易过拟合,而且输入数据需要按label进行特别的排序。目前已有很多改进的版本,例如Improved Triplet Loss。
Center Loss
centerloss是2016年ECCV提出来的,具体参考论文A Discriminative Feature Learning Approach for Deep Face Recognition,目的是为了解决softmax类内间距太大的问题,通过添加centerloss让简单的softmax能够训练出更有内聚性的特征,使学习到的特征具有更好的泛化性和辨别能力,具体示意图如下: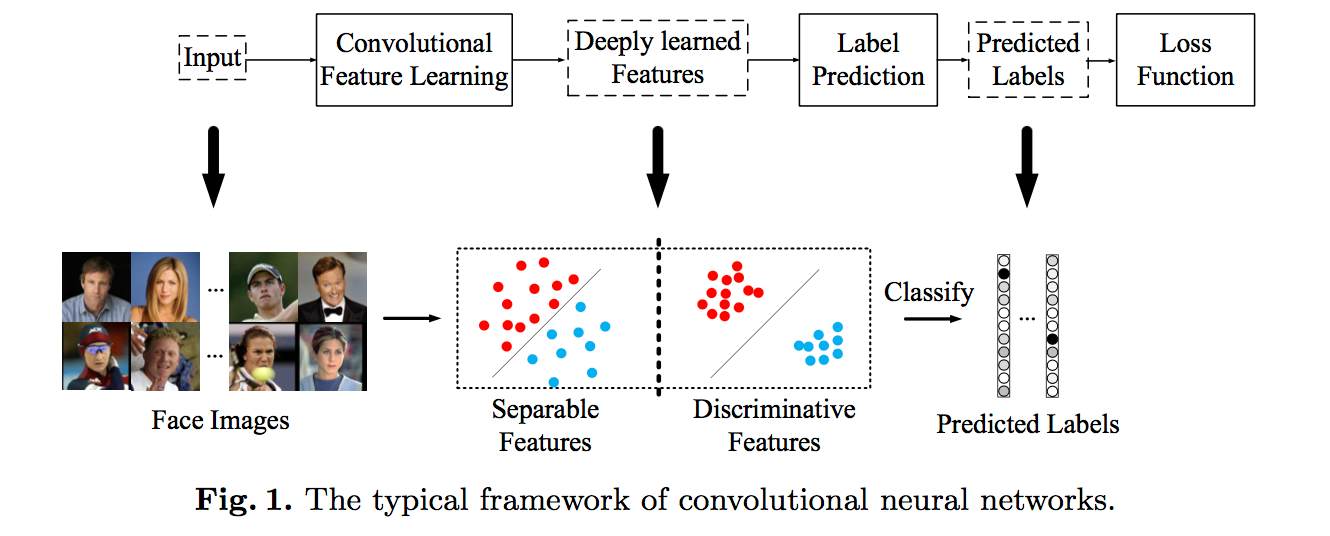
相对于triplet和contrastive loss来说,centerloss通过惩罚每个种类的样本和该种类样本中心的偏移,使得同一种类的样本尽量聚合在一起,而不需要像前两者那样构造大量的训练对,所以网络收敛的速度相对更快。
在人脸识别运用中,centerloss与softmax连接应用方式如下: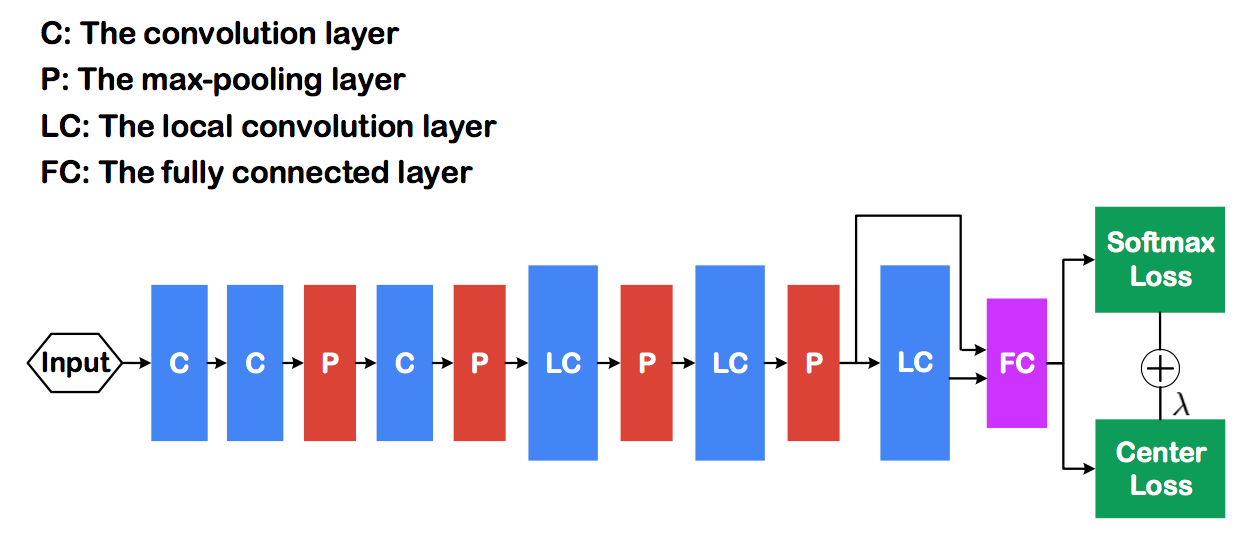
softmax + centerloss组成的loss function如下: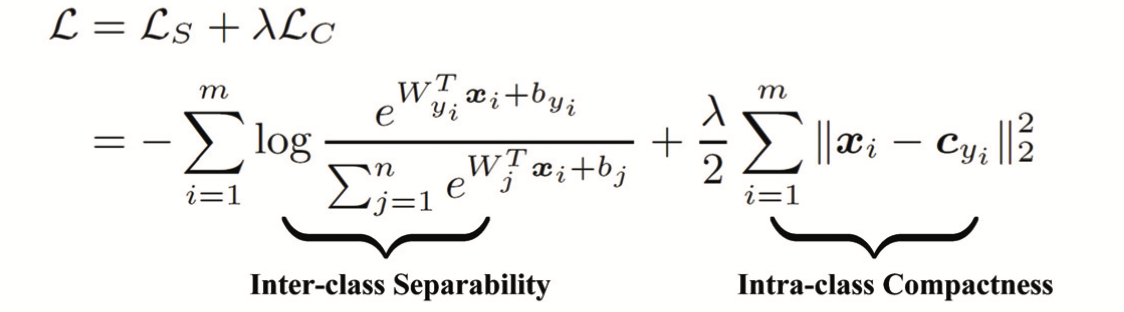
Ls为softmax损失函数,它可以学习到可分类特征,但无法保证特征类内间距,而Lc通过约束特征到其中心点的距离来提高特征的内聚性,两者结合可以保证特征的可分性和内聚性。
在mnist数据集上进行测试,当alpha = 0.5时,不同lamda对应的特征表现如下: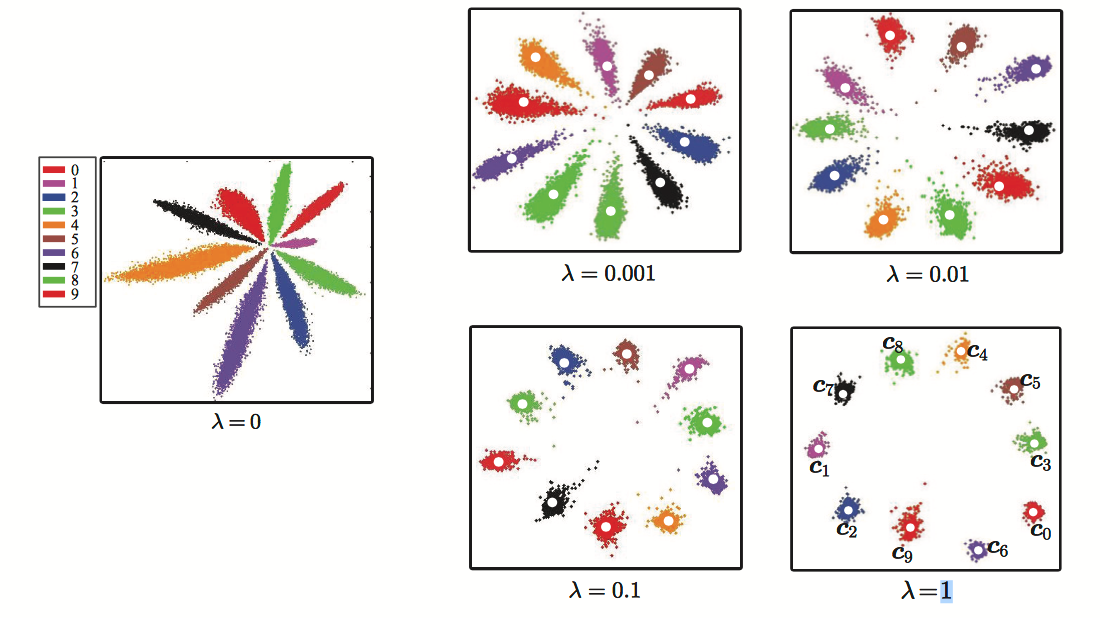
当lamda = 0时,仅使用softmax,学习到特征虽然可分,但是类内间距太大。
在LFW测试集上测试表现如下(其中alpha代表了centerloss的学习率):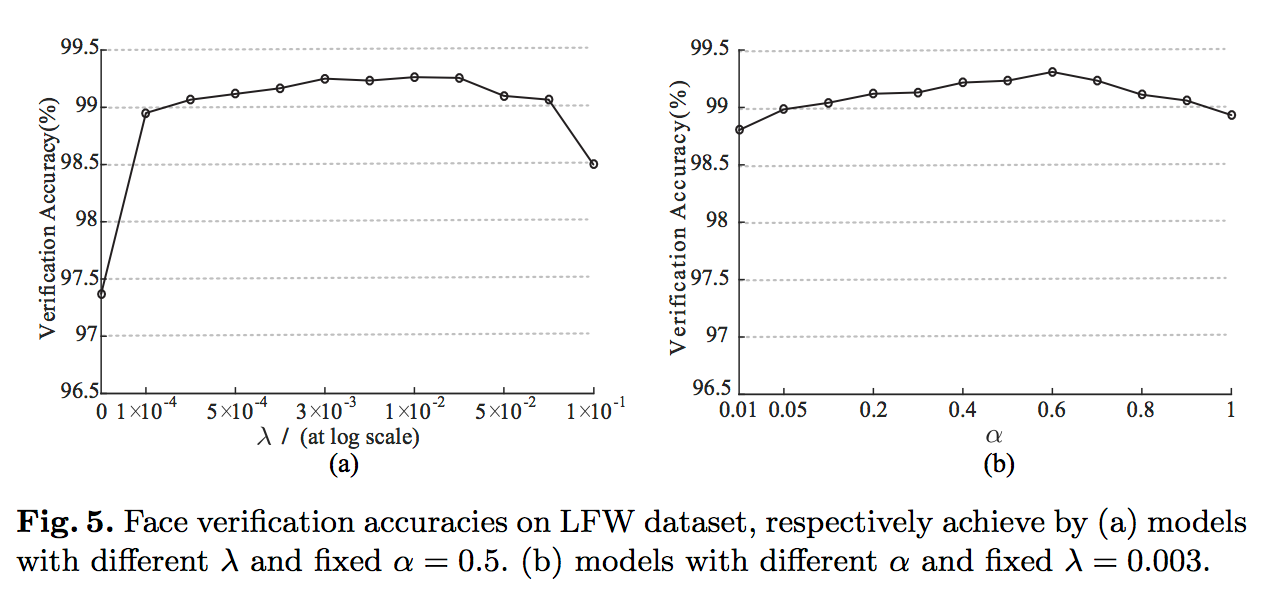
当alpha = 0.5, lamda = 0.003时,对应model C,LFW和YTF测试结果如下: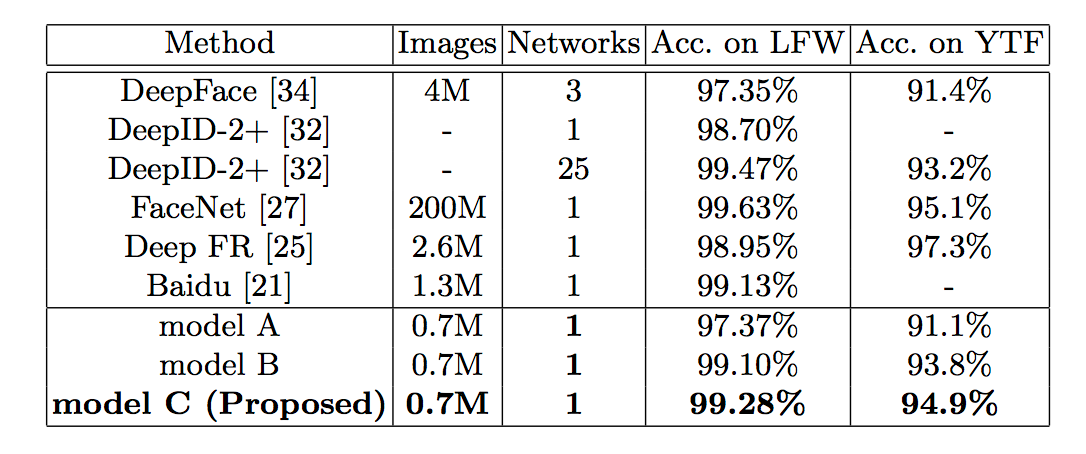
Megaface的Identification任务测试结果如下: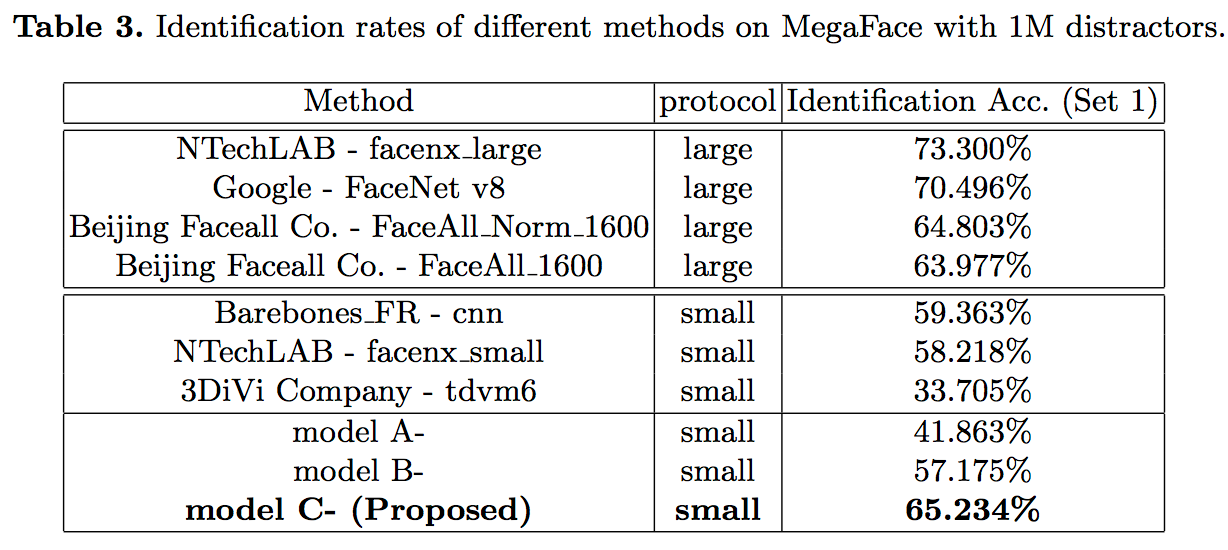
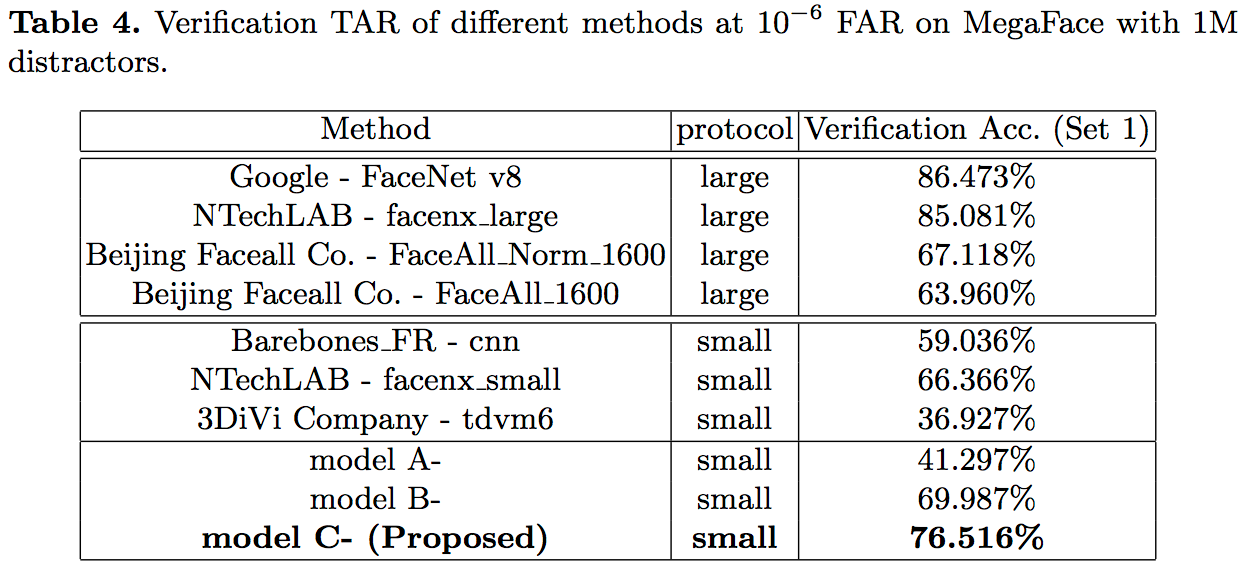
Megaface的Verification任务测试结果如下: