算法简介
近几年来,随着卷积神经网络的迅速发展,GoogleNet、VGGNet、ResNet等模型在各种计算机视觉任务上得到广泛的应用。但随着网络层数的加深,网络在训练过程中的前传信号和梯度信号在经过很多层之后可能会逐渐消失。目前很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等,这些算法的核心都在于:创建了一个跨层连接来连通网路中前后层。
DenseNet就是基于这个核心理念设计了一种全新的连接模式,在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来,具体参考2017CVPR最佳论文Densely Connected Convolutional Networks。
DenseNet的网络结构如下:
注意由多个dense block组成,单个dense block的结构如下:
ResNet单元模块表达式如下:
l表示层,xl表示l层的输出,Hl表示一个非线性变换。所以对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换。
而对于Dense Block而言: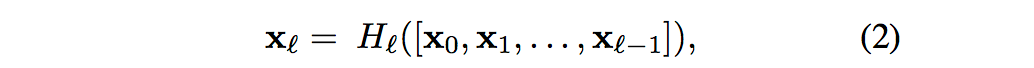
[x0,x1,…,xl-1]表示将0到l-1层的输出feature map做concatenation,concatenation是做通道的合并,而resnet是做值的相加,通道数是不变的。Hl包括BN,ReLU和3*3的卷积。
DenseNet与ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效。
网络结构
针对ImageNet物体识别任务论文分别设计了DesNet-121(k=32)、DesNet-169(k=32)、DesNet-201(k=32)和DesNet-161(k=48)四种网络结构。其网络的组织形式和ResNet 类似,也是分为4个阶段,将原先的ResNet的单元模块进行了替换,下采样过程略有不同。整体结构设计如下所示:
k为增长率。增长率是指每个单元模块最后那个3x3的卷积核的数量。由于每个单元模块最后是以Concatenate的方式来进行连接的,所以每经过一个单元模块,下一层的特征维度就会增长 k。它的值越大意味着在网络中流通的信息也越大,相应地网络的能力也越强,但是整个模型的尺寸和计算量也会变大。
上表中每个dense block的3*3卷积前面都包含了一个1*1的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。另外作者为了进一步压缩参数,在每两个dense block之间又增加了1*1的卷积操作。因此在后面的实验对比中,如果你看到DenseNet-C这个网络,表示增加了这个Translation layer,该层的1*1卷积的输出channel默认是输入channel到一半。如果你看到DenseNet-BC这个网络,表示既有bottleneck layer,又有Translation layer。
bottleneck
每个Dense Block中都包含很多个子结构,以DenseNet-169的Dense Block(3)为例,包含32个1*1和3*3的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),那么如果不做bottleneck操作,第32层的3*3卷积操作的输入就是31*32+(上一个Dense Block的输出channel),近1000了。而加上1*1的卷积,代码中的1*1卷积的channel是growth rate*4,也就是128,然后再作为3*3卷积的输入。这就大大减少了计算量,这就是bottleneck。
transition layer
transition layer放在两个Dense Block中间,是因为每个Dense Block结束后的输出channel个数很多,需要用1*1的卷积核来降维。还是以DenseNet-169的Dense Block(3)为例,虽然第32层的3*3卷积输出channel只有32个(growth rate),但是紧接着还会像前面几层一样有通道的concat操作,即将第32层的输出和第32层的输入做concat,前面说过第32层的输入是1000左右的channel,所以最后每个Dense Block的输出也是1000多的channel。因此这个transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。文中还用到dropout操作来随机减少分支,避免过拟合。
实验结果
作者在不同数据集上采用的DenseNet网络会有一点不一样,比如在Imagenet数据集上,DenseNet-BC有4个dense block,但是在别的数据集上只用3个dense block。其他更多细节可以看论文3部分的Implementation Details。训练的细节和超参数的设置可以看论文4.2部分,在ImageNet数据集上测试的时候有做224*224的center crop。
在ImageNet上的实验结果如下:
左图表示参数量和错误率的关系,右图表示模型测试的计算量和错误率的关系。从上图可以看出,在达到相同精度时,DenseNet的参数量和计算量均为ResNet的一半左右。但是DenseNet网络不能设计地特别深,因为随着DenseNet网络层数的增加,模型的特征维度会线性增长,使得在训练过程中的计算量和显存开销也会爆发地增长。
在三个数据集(C10,C100,SVHN)上和其他算法的对比结果如下: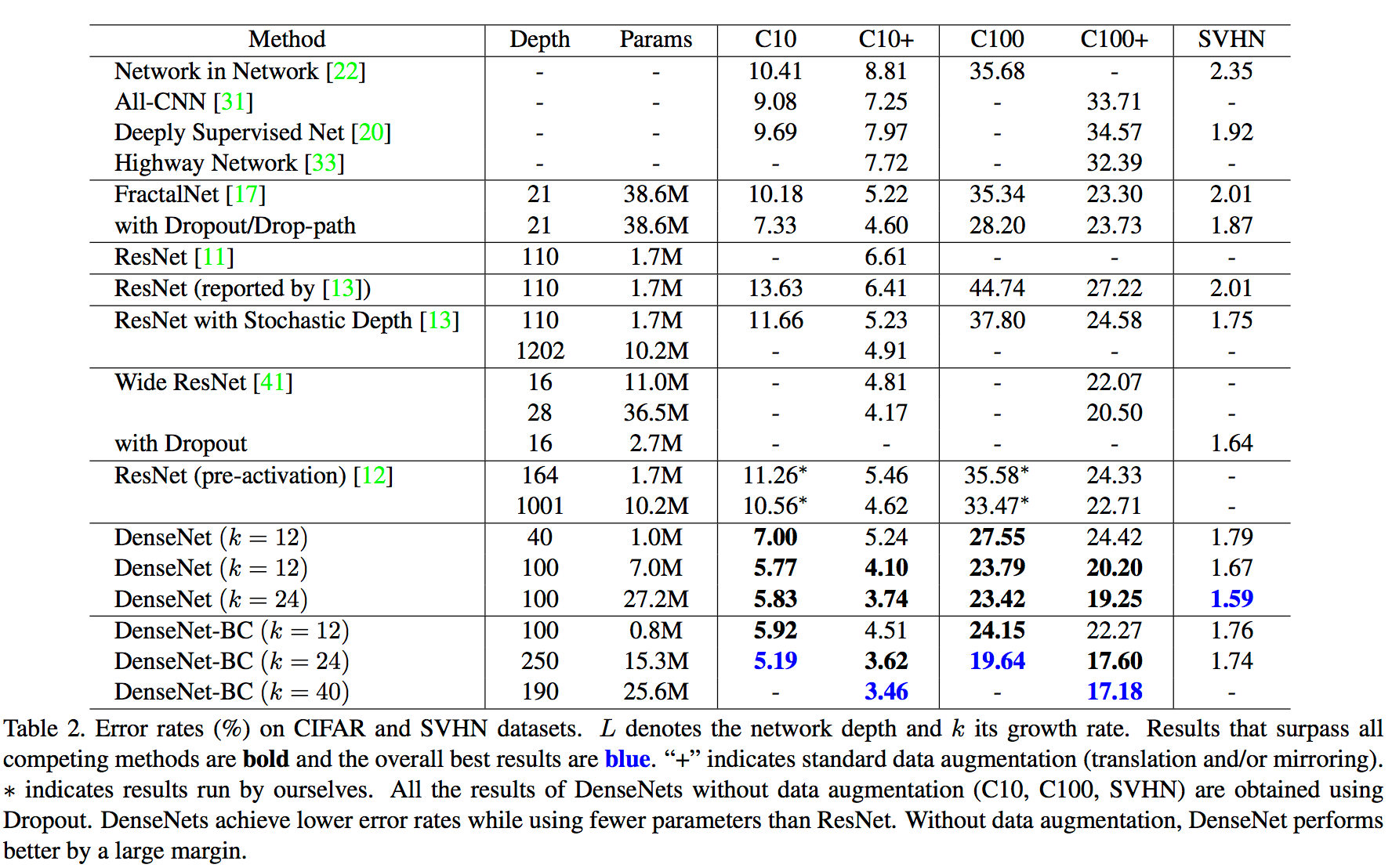
DenseNet-BC的网络参数和相同深度的DenseNet相比确实减少了很多!参数减少除了可以节省内存,还能减少过拟合。对于SVHN数据集,DenseNet-BC的结果并没有DenseNet(k=24)的效果好,作者认为原因主要是SVHN这个数据集相对简单,更深的模型容易过拟合。在表格的倒数第二个区域的三个不同深度L和k的DenseNet的对比可以看出随着L和k的增加,模型的效果是更好的。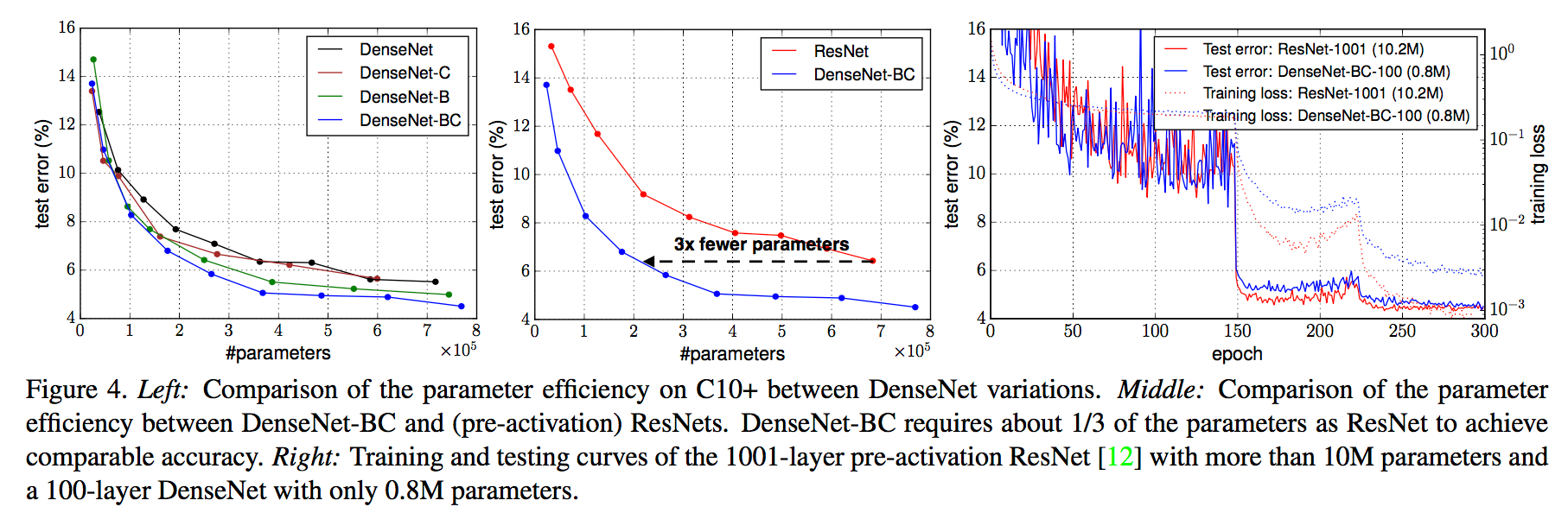
左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果。
总结而言:DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。
参考文章:
http://blog.csdn.net/u014380165/article/details/75142664
