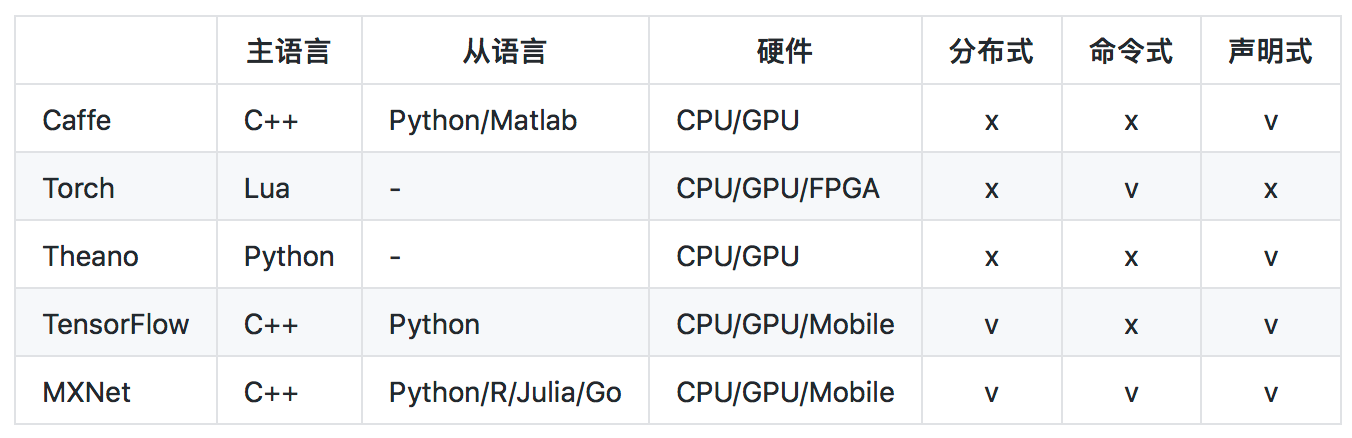
ResNet
ResNet——MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。
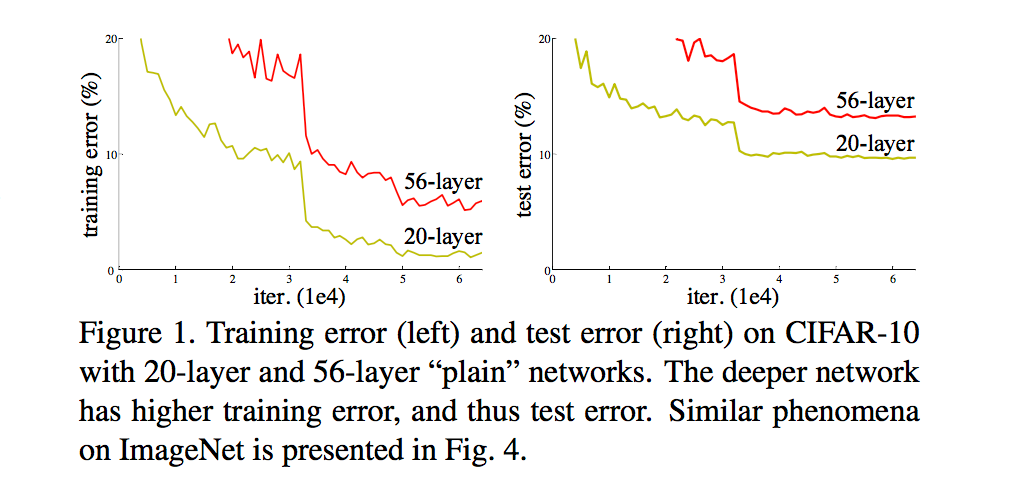
ResNet最根本的动机就是解决所谓的“退化”问题,即当模型的层次加深时,错误率却提高了,如下图: